Arquitectura Hexagonal (Puertos y Adaptadores)
La arquitectura hexagonal (también conocida como patrón de puertos y adaptadores) es un estilo de arquitectura de software propuesto por Alistair Cockburn en 2005 (Patrón de arquitectura hexagonal - AWS Guía prescriptiva). Su objetivo principal es lograr un bajo acoplamiento entre la lógica de negocio de una aplicación y los detalles de implementación de la infraestructura (bases de datos, interfaces de usuario, frameworks, etc.). En lugar de depender directamente de estas tecnologías externas, la aplicación central se comunica con ellas a través de interfaces bien definidas, llamadas puertos, y de implementaciones de esas interfaces, llamadas adaptadores.
Esto permite que los componentes de la aplicación se puedan desarrollar, probar y modificar de forma aislada, sin depender de una base de datos o una interfaz de usuario específica. En pocas palabras, la arquitectura hexagonal busca separar el código del dominio (negocio) de los detalles externos, resolviendo problemas comunes como la contaminación de la lógica de negocio en la capa de presentación o la dependencia excesiva en una base de datos concreta.
En las arquitecturas tradicionales, era frecuente que parte de la lógica de negocio terminara “filtrándose” hacia la interfaz gráfica o hacia el código de acceso a datos, lo que dificultaba las pruebas automatizadas y la evolución del sistema.
La arquitectura hexagonal surge como respuesta a estas limitaciones, proponiendo una organización donde el núcleo de la aplicación no conoce nada acerca de las tecnologías externas con las que se integra. Gracias a esta separación, una aplicación hexagonal puede ser ejecutada de la misma forma por una interfaz gráfica, por una API, por pruebas automatizadas o por un script batch.
Asimismo, la aplicación puede ejecutarse sin una base de datos real (por ejemplo, usando una base de datos en memoria o simulada) y seguir funcionando correctamente.
En esencia, elimina el acoplamiento rígido entre la lógica de negocio y los mecanismos de entrada/salida, facilitando el cambio de tecnologías, la reutilización de la lógica central y la realización de pruebas unitarias en aislamiento.
Comparación con otras arquitecturas (MVC, en capas, etc.)
Para entender mejor la arquitectura hexagonal, conviene compararla con otros enfoques comunes como la arquitectura en capas (o n-tier) y el patrón MVC (Modelo-Vista-Controlador):
Arquitectura en tres capas tradicional: la capa de Presentación invoca la lógica de Dominio, que a su vez llama a la capa de Acceso a datos, la cual interactúa con la base de datos. En este modelo lineal, las dependencias suelen dirigirse desde la interfaz de usuario hacia la base de datos, y con frecuencia la lógica de negocio termina dependiendo de detalles de la capa inferior (por ejemplo, llamadas SQL o formatos de datos específicos).
-
Arquitectura en capas tradicional: En una aplicación de tres capas típica, tenemos la capa de Presentación (UI), la capa de Dominio (negocio) y la capa de Acceso a Datos. Cada capa conoce o invoca a la que está debajo: la UI llama a la lógica de negocio, y esta a su vez accede a la base de datos. Este enfoque separa responsabilidades hasta cierto punto, pero no impone completamente la inversión de dependencias. Es común que el dominio dependa de clases o frameworks de acceso a datos (por ejemplo, modelos de ORM) o que la lógica se mezcle con detalles de la UI. Si queremos probar la lógica de negocio en aislamiento, a veces es difícil porque está entrelazada con la base de datos o la interfaz gráfica.
-
MVC (Modelo-Vista-Controlador): MVC es un patrón arquitectónico muy usado, especialmente en aplicaciones web. Ofrece una separación entre la Vista (interfaz de usuario), el Modelo (que a menudo incluye la lógica de negocio y datos) y el Controlador (que actúa de intermediario). Sin embargo, en muchas implementaciones MVC (por ejemplo, frameworks web tradicionales), el Modelo termina incluyendo detalles de la base de datos (por ejemplo, entidades del ORM) y la Vista puede estar acoplada a tecnologías específicas. Aunque MVC separa la presentación de la lógica, no garantiza que el núcleo de negocio esté completamente aislado de infraestructuras externas. Un cambio en la capa de datos puede impactar en el modelo, y pruebas unitarias puras pueden requerir instancias de base de datos o entorno web simulado.
-
Hexagonal vs tradicional: La arquitectura hexagonal lleva la idea de separación de capas más allá, aplicando el Principio de Inversión de Dependencias de forma estricta. A diferencia de MVC o la clásica 3-capas, en hexagonal el flujo de dependencias se invierte: el dominio no depende de la base de datos ni de la UI; son estos detalles (implementados como adaptadores) los que dependen del dominio a través de interfaces. Otra diferencia es que hexagonal no impone una forma unidireccional de entrada/salida; en lugar de una estructura lineal, imagina el sistema como un núcleo rodeado de varios conectores (puertos) hacia el exterior. Esto significa que podemos tener múltiples mecanismos de entrada (por ejemplo, una UI web, una aplicación de consola, pruebas automatizadas) coexistiendo y utilizando la misma lógica de negocio, así como múltiples mecanismos de salida (varios servicios externos, diferentes bases de datos, colas de mensajes, etc.), todo al mismo tiempo y todos intercambiables. Este enfoque es más flexible que las capas tradicionales, que no describen fácilmente múltiples puntos de entrada/salida simétricos.
En resumen, MVC y la arquitectura por capas buscan separar responsabilidades pero suelen dejar al dominio expuesto a los detalles (tipos de datos de la BD, detalles de la UI, etc.). La arquitectura hexagonal, en cambio, propone que el dominio sea agnóstico de esos detalles, logrando un sistema más modular y fácil de cambiar.
Conceptos clave: Dominio, Puertos, Adaptadores e Independencia de infraestructura
Veamos los elementos fundamentales de la arquitectura hexagonal y cómo encajan entre sí:
-
Dominio (núcleo de la aplicación): Representa la lógica de negocio pura de la aplicación, es decir, las reglas, procesos y entidades que modelan el problema que el software resuelve. El dominio se encuentra en el centro del diseño (por eso se habla metafóricamente de un “hexágono” rodeando al núcleo). Todo el código del dominio debe ser independiente de detalles tecnológicos externos. Aquí definimos las entidades del negocio (por ejemplo, en una app de tareas, entidades como Tarea, Usuario, etc.) y la lógica asociada (por ejemplo, cómo marcar una tarea como completada, reglas de validación, cálculos, etc.). También pueden existir objetos como servicios de dominio o casos de uso que orquestan operaciones del negocio. En arquitectura hexagonal, el dominio puede declarar interfaces que necesita para realizar su trabajo (por ejemplo, una interfaz de Repositorio para almacenar tareas), pero no sabe nada de cómo esas interfaces serán implementadas. En resumen, el dominio es el corazón de la aplicación y permanece completamente desacoplado de la infraestructura externa
-
Puertos: En hexagonal, un puerto es una interfaz (un contrato) que define cómo puede interactuar algo externo con el dominio, o cómo el dominio se comunica con algo externo. Podemos diferenciar dos tipos de puertos:
-
- Puertos de entrada (primarios): Son interfaces expuestas por el núcleo de la aplicación hacia el mundo exterior. Representan casos de uso o funcionalidades del sistema que pueden ser invocadas. Por ejemplo, un puerto de entrada podría ser una interfaz
ServicioDeTareascon métodos comocrearTarea,listarTareas, etc. Estos puertos de entrada definen lo que el dominio sabe hacer, y serán implementados o invocados por adaptadores de entrada (como un controlador web, una interfaz de línea de comando, etc.). Un usuario, programa o prueba automatizada utilizará un adaptador (por ejemplo, una API REST) que a su vez llamará a estos puertos de entrada.
- Puertos de salida (secundarios): Son interfaces que el núcleo requiere para interactuar con el exterior. Representan cosas que el dominio necesita que alguien más haga. Por ejemplo, podría haber un puerto de salida
RepositorioDeTareas(una interfaz) que define operaciones para guardar o recuperar tareas. El dominio (quizá en su lógica de un caso de uso) llamará a métodos de esta interfaz, sin saber qué hay detrás. Estos puertos de salida serán implementados por adaptadores de infraestructura, como por ejemplo una clase que guarda las tareas en una base de datos específica. En otros contextos, también se les llama interfaces de driven adapters (adaptadores conducidos) porque el dominio las “conduce” esperando una respuesta.
En ambos casos, un puerto es simplemente una abstracción: define una funcionalidad o punto de interacción, pero no impone una implementación concreta. Los puertos garantizan la independencia de la lógica de negocio respecto a los detalles externos. Mientras el dominio hable con el “mundo exterior” solo a través de puertos, podemos cambiar completamente la tecnología subyacente de ese mundo exterior sin tocar el dominio.
- Puertos de entrada (primarios): Son interfaces expuestas por el núcleo de la aplicación hacia el mundo exterior. Representan casos de uso o funcionalidades del sistema que pueden ser invocadas. Por ejemplo, un puerto de entrada podría ser una interfaz
-
Adaptadores: Un adaptador es el componente que conecta una implementación tecnológica concreta a un puerto correspondiente. Siguiendo los dos tipos de puertos, tenemos:
- Adaptadores primarios (de entrada o driving adapters): Son los que invocan al dominio a través de puertos de entrada. Actúan desde “fuera hacia adentro”. Ejemplos: un controlador HTTP que recibe una petición REST y llama al servicio de dominio adecuado; una interfaz gráfica que al hacer clic en un botón invoca una operación del núcleo; un test automatizado que instancia directamente un caso de uso; un script de consola que crea objetos del dominio y los ejecuta. Estos adaptadores toman las entradas externas (una solicitud web, por ejemplo), las transforman si es necesario, y llaman al puerto de entrada apropiado. También son responsables de tomar la respuesta del dominio (por ejemplo un objeto de dominio o resultado) y traducirla a algo que el exterior entienda (por ejemplo, formatear una respuesta JSON, mostrar texto en consola, etc.). Importante: el adaptador de entrada conoce el puerto de entrada (interfaz de dominio) que está llamando, pero el dominio no sabe nada del adaptador ni de quién lo está llamando.
- Adaptadores secundarios (de salida o driven adapters): Son los que implementan los puertos de salida requeridos por el dominio. Actúan desde “dentro hacia afuera”. Ejemplos: una clase repositorio que guarda datos en MySQL implementando la interfaz
RepositorioDeTareas; un cliente HTTP que llama a un servicio externo implementando una interfaz de ServicioNotificaciones que el dominio usa; una implementación que envía un email mediante SMTP para un puerto de notificación del dominio, etc. Estos adaptadores se enchufan al dominio proporcionando la funcionalidad concreta que el núcleo necesita. El dominio invoca un método de la interfaz (puerto de salida) y el adaptador lo recibe, ejecutando la tecnología real (consultar la base de datos, enviar la cola de mensaje, etc.). Nuevamente, el adaptador sabe del dominio (implementa su interfaz), pero el dominio no sabe nada de la clase adaptadora concreta ni de cómo realiza su tarea.
- Adaptadores primarios (de entrada o driving adapters): Son los que invocan al dominio a través de puertos de entrada. Actúan desde “fuera hacia adentro”. Ejemplos: un controlador HTTP que recibe una petición REST y llama al servicio de dominio adecuado; una interfaz gráfica que al hacer clic en un botón invoca una operación del núcleo; un test automatizado que instancia directamente un caso de uso; un script de consola que crea objetos del dominio y los ejecuta. Estos adaptadores toman las entradas externas (una solicitud web, por ejemplo), las transforman si es necesario, y llaman al puerto de entrada apropiado. También son responsables de tomar la respuesta del dominio (por ejemplo un objeto de dominio o resultado) y traducirla a algo que el exterior entienda (por ejemplo, formatear una respuesta JSON, mostrar texto en consola, etc.). Importante: el adaptador de entrada conoce el puerto de entrada (interfaz de dominio) que está llamando, pero el dominio no sabe nada del adaptador ni de quién lo está llamando.
-
Independencia de la infraestructura: Este principio es la piedra angular del patrón. La lógica de negocio no depende de bases de datos, ni de frameworks, ni de nada externo; solo depende de sus puertos (interfaces). Por lo tanto, podemos cambiar la infraestructura sin cambiar el dominio. Si mañana decidimos reemplazar una base de datos SQL por una NoSQL, o exponer el sistema por mensajería en lugar de HTTP, lo podemos lograr escribiendo nuevos adaptadores que cumplan con los mismos puertos. La inversión de control es total: el núcleo dicta el contrato (puerto), los detalles externos se ajustan a él (adaptador). Esto facilita enormemente la pruebas automatizadas: podemos crear stubs o mocks de los adaptadores para probar el dominio en aislamiento, o incluso usar adaptadores falsos (por ejemplo, una base de datos en memoria) durante el desarrollo. También evita el bloqueo tecnológico: la aplicación no queda casada para siempre con una herramienta o proveedor, se puede migrar en el futuro con un impacto mínimo en la lógica central.
Para visualizar estos conceptos, imaginemos el dominio como el interior de un hexágono y los puertos como lados por donde conectan adaptadores externos:
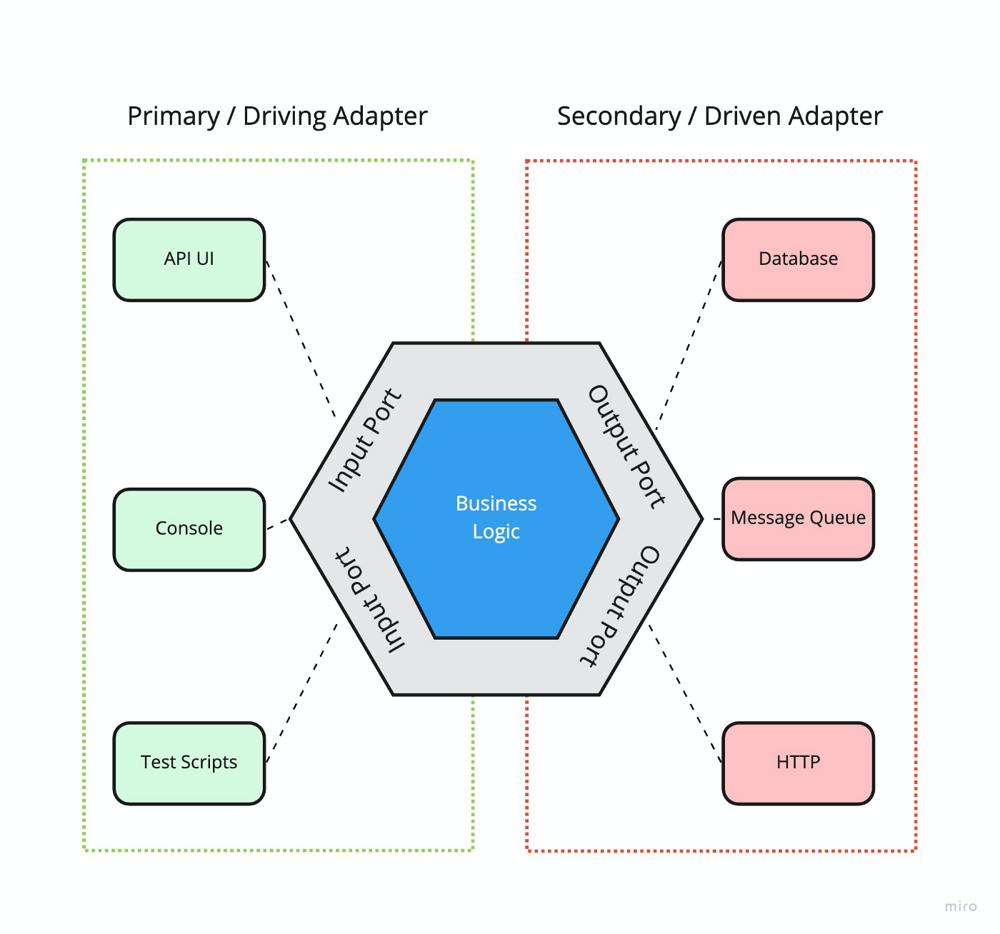
Diagrama conceptual de la arquitectura hexagonal: en el centro está la lógica de negocio (hexágono azul). El hexágono gris representa los puertos de entrada y salida que rodean al núcleo (etiquetados aquí como Input Port y Output Port). A la izquierda (marco verde) vemos adaptadores primarios (Primary/Driving Adapter, por ejemplo una UI API, consola o scripts de prueba) que invocan funcionalidades del dominio a través de puertos de entrada. A la derecha (marco rojo) se ilustran adaptadores secundarios (Secondary/Driven Adapter, por ejemplo base de datos, cola de mensajes, API HTTP externa) que son utilizados por el dominio a través de puertos de salida. Obsérvese que el núcleo de negocio (Business Logic) no tiene dependencias directas con ninguno de estos componentes externos; se comunica únicamente vía puertos.
Beneficios de usar la arquitectura hexagonal
Aplicar arquitectura hexagonal conlleva varias ventajas significativas:
- Aislamiento del dominio: La lógica de negocio permanece limpia, enfocada en las reglas del negocio y libre de frameworks o API externas. Esto hace que el dominio sea independiente del framework, de la base de datos y de la interfaz de usuario (Arquitectura Hexagonal. O el patrón puertos y adaptadores | by Edu Salguero | Medium), facilitando su evolución.
- Testabilidad: Al no depender de entornos externos, el núcleo se puede probar fácilmente con pruebas unitarias. Podemos usar dobles de prueba (mocks, stubs) para simular los adaptadores y verificar las reglas de negocio en aislamiento. Ya no es necesario levantar toda la app, una base de datos o una interfaz gráfica para probar un cálculo o regla; las pruebas son más rápidas y fiables.
- Flexibilidad y capacidad de cambio: Si en un futuro necesitamos cambiar una herramienta o tecnología, la arquitectura hexagonal lo hace más sencillo. Por ejemplo, podríamos sustituir una base de datos relacional por una en memoria, o un servicio REST por otro gRPC, simplemente escribiendo nuevos adaptadores que cumplan los mismos puertos, sin tocar el código de negocio (¿Qué es la arquitectura hexagonal? Aplicación, puerto y adaptador). Esto permite evitar bloqueos tecnológicos y adaptarse a requisitos cambiantes con menor costo.
- Múltiples puntos de entrada: Podemos tener varias formas de interactuar con la aplicación simultáneamente. Por ejemplo, la misma lógica de tareas podría ser usada por una interfaz web, una aplicación móvil, un script CLI y pruebas automatizadas, todo gracias a diferentes adaptadores de entrada reutilizando los mismos puertos. Esto promueve la reutilización de la lógica y reduce duplicación.
- Mantenibilidad y escalabilidad: Una aplicación organizada de este modo suele ser más fácil de entender y mantener. Cada pieza tiene responsabilidades claras (cohesión) y las dependencias están controladas (bajo acoplamiento). Nuevos desarrolladores pueden entender la lógica sin distraerse con detalles de infraestructura. Además, escalar partes del sistema (por ejemplo, migrar la base de datos, añadir una nueva forma de entrada) se vuelve más sencillo al estar los componentes bien separados. Un sistema hexagonal tiende a ser más tolerante al cambio y permite iterar más rápido sin romper todo el funcionamiento (Arquitectura Hexagonal. O el patrón puertos y adaptadores | by Edu Salguero | Medium).
- Simetría de la solución: Hexagonal enfatiza que los “lados” de la aplicación (entrada y salida) son conceptualmente similares. Esto proporciona una visión consistente: tanto un usuario humano como una base de datos se conectan al núcleo mediante un puerto. Esta simetría ayuda a aplicar buenas prácticas en ambos lados (por ejemplo, evitar también acoplarse a detalles de una API externa, igual que evitamos acoplarnos a detalles de la UI).
Por estas razones, la arquitectura hexagonal se ha vuelto popular para proyectos que requieren longevidad y fácil mantenimiento. Grandes empresas la han utilizado para construir sistemas modulares; por ejemplo, Netflix ha mencionado su uso de una arquitectura hexagonal para dividir su plataforma en servicios independientes y permitir intercambiar fuentes de datos sin afectar la lógica central (Arquitectura Hexagonal | Blog Santander Open Academy). En general, es un patrón que favorece la calidad interna del software, facilitando su evolución en el tiempo.
Desventajas y consideraciones al usar hexagonal
Como cualquier patrón de arquitectura, la hexagonal también tiene sus desventajas o costos asociados, especialmente si se aplica en contextos inadecuados:
- Mayor complejidad inicial: Adoptar hexagonal agrega abstracciones (interfaces, adaptadores adicionales) que pueden hacer que el diseño sea más complejo que un enfoque monolítico simple. Para proyectos pequeños o prototipos, definir puertos y adaptadores podría sentirse exagerado. Si la lógica de negocio es trivial, la sobrecarga de código puede no justificarse.
- Más código y estructuras: Al introducir capas de indirección (por ejemplo, clases de repositorio, interfaces para cada dependencia, etc.), el número de archivos y clases aumenta. Esto puede hacer que inicialmente sea más difícil entender el flujo de la aplicación para nuevos desarrolladores, comparado con un proyecto “simple” donde todo está junto. Requiere disciplina para mantener la trazabilidad de “quién llama a quién” a través de las interfaces.
- Curva de aprendizaje: Aunque el concepto no es extremadamente complicado, a muchos desarrolladores sin experiencia en este patrón les puede costar al inicio visualizar cómo encaja todo. Términos como puertos, adaptadores, primario, secundario, pueden confundir si no se explican bien. Implementarla correctamente requiere comprender principios de diseño (inyección de dependencias, inversión de dependencia). Si un miembro del equipo no sigue la convención, podría romper la arquitectura sin darse cuenta.
- Dispersión de la lógica: Si no se tiene cuidado, puede suceder que la lógica del negocio quede demasiado fragmentada entre el dominio y los adaptadores. Por ejemplo, cierta validación podría indebidamente implementarse en un adaptador en lugar del dominio, causando confusión. Una arquitectura hexagonal mal implementada puede derivar en un sistema donde es difícil seguir la lógica porque está repartida en demasiados sitios.
- Diseño inicial más pesado: Requiere pensar desde el comienzo qué puertos serán necesarios, qué adaptadores habrá que implementar, etc. Es una inversión de tiempo y esfuerzo de diseño que puede no rendir frutos hasta que el sistema crezca. Por tanto, en las etapas iniciales del proyecto, el desarrollo puede ser más lento en comparación con “tirar código rápido” acoplado.
- Riesgo de sobreingeniería: Si se aplica sin verdadera necesidad, se corre el riesgo de crear una solución más compleja de lo requerido. Una arquitectura hexagonal mal utilizada puede terminar siendo costosa en tiempo y recursos, sin beneficios claros porque tal vez el sistema nunca necesitó esa flexibilidad (por ejemplo, proyectos de corta vida o muy sencillos).
En resumen, la arquitectura hexagonal no es una bala de plata. Debe evaluarse si el nivel de flexibilidad y desacoplo que ofrece es realmente necesario para el proyecto en cuestión. En sistemas complejos y de gran tamaño, suele pagar dividendos en mantenibilidad. En proyectos pequeños, podría introducir complejidad innecesaria. La clave es aplicar el patrón de manera adecuada y mantener una buena disciplina de diseño para obtener sus beneficios y mitigar sus costos.
Ejemplo práctico en JavaScript: gestión de tareas
A continuación, veamos cómo podríamos estructurar una pequeña aplicación de gestión de tareas (to-do list) utilizando arquitectura hexagonal. Imaginemos que queremos una aplicación que permita crear tareas, listarlas, marcarlas como completadas, etc., y deseamos que la lógica de tareas sea independiente de cómo almacenamos las tareas o de cómo las invocamos (puede ser via web, consola, etc.). Usaremos JavaScript (Node.js) sin ningún framework específico para simplificar.
Estructura de carpetas y componentes
Primero, definamos la posible estructura de directorios de nuestra aplicación siguiendo este patrón. Podría ser algo así:
src/
├── dominio/ # Núcleo de la aplicación: entidades y lógica de negocio
│ ├── Tarea.js # Entidad de Dominio: define la estructura de una Tarea
│ ├── TareaServicio.js # Servicio de dominio (casos de uso) para tareas
│ └── puertos/
│ └── RepositorioTareas.js # Puerto de salida: interfaz de repositorio
├── adaptadores/
│ ├── entrada/ # Adaptadores de entrada (p.ej., controladores, interfaces)
│ │ └── cli.js # Ejemplo de interfaz de consola como entrada (opcional)
│ └── persistencia/ # Adaptadores de salida (implementaciones de puertos)
│ └── RepoMemoriaTareas.js # Implementación en memoria de RepositorioTareas
└── app.js # Punto de entrada de la aplicación (configura adaptadores y arranca)
-
En la carpeta
dominio/reside toda la lógica de negocio. Allí tenemos la definición de la entidadTarea(que podría ser una clase o función constructora que encapsula los datos de una tarea, p. ej. id, título, estado), y un servicio de dominioTareaServicioque contiene operaciones sobre las tareas (crear una nueva, marcarlas, listarlas). También dentro dedominiodefinimos los puertos que necesita el dominio: por ejemplo, un puerto de salidaRepositorioTareas(una interfaz que declara métodos comoguardar(tarea)oobtenerTodas()para persistir tareas). Notar queRepositorioTareas.jsno tendrá una implementación concreta, solo la definición de los métodos (en JavaScript, al no haber interfaces formales, podemos definir una clase abstracta o usar JSDoc para indicar el contrato). -
En la carpeta
adaptadores/entrada/podríamos ubicar los adaptadores primarios. Para este ejemplo sencillo, podríamos omitir implementar una interfaz de usuario real; en su lugar, nuestro archivoapp.jsactuará como simulador de entrada (ejecutando ciertas operaciones del servicio de tareas). Si quisiéramos, podríamos crear un adaptador de consola (cli.js) que lea comandos del usuario y llame al servicio de tareas. -
En
adaptadores/persistencia/colocamos los adaptadores secundarios de salida. ImplementaremosRepoMemoriaTareas.jsque es un repositorio en memoria para almacenar las tareas en una lista (simulando una base de datos temporal). En un caso real, podríamos tener otro adaptador, digamosRepoArchivoTareas.jspara guardar en archivo, oRepoMongoTareas.jspara una base de datos MongoDB, etc., todos implementando la misma interfaz de Repositorio. -
El archivo
app.jses el punto de arranque: aquí configuramos las dependencias. Por ejemplo, crearemos una instancia deRepoMemoriaTareasy se la inyectaremos al servicio de dominioTareaServicio. Luego, podríamos invocar algunas operaciones del servicio (como añadir tareas) y mostrar resultados, demostrando cómo interactúa todo junto. En una aplicación real, este podría ser el lugar donde conectamos, por ejemplo, las rutas HTTP (adaptador de entrada) con los servicios de dominio y estos con los repositorios (adaptadores de salida).
Ahora pasemos a ver fragmentos de código para estos componentes:
Dominio: entidad y puerto de repositorio
En el dominio definiremos la entidad Tarea y la interfaz del repositorio de tareas (puerto de salida):
// dominio/Tarea.js (Entidad de dominio)
class Task {
constructor(id, title, completed = false) {
this.id = id;
this.title = title;
this.completed = completed;
}
// Método de dominio para marcar como completada
marcarComoCompletada() {
this.completed = true;
}
}
// dominio/puertos/RepositorioTareas.js (Puerto de salida - interfaz)
class TaskRepository {
/**
* Agrega una tarea al repositorio.
* @param {Task} task
*/
add(task) {
throw new Error('Método no implementado');
}
/**
* Obtiene todas las tareas del repositorio.
* @returns {Task[]}
*/
findAll() {
throw new Error('Método no implementado');
}
// Podríamos definir más métodos según necesidades (ej: findById, remove, etc.)
}
En el código anterior, Task es una clase de dominio que representa la entidad Tarea con sus propiedades (id, title, completed). Incluimos un método marcarComoCompletada() como ejemplo de lógica dentro de la entidad (aunque en este caso es trivial).
Por otro lado, TaskRepository es una clase que actúa como interface (puerto) de repositorio de tareas. En JavaScript no tenemos interfaces nativas, así que usamos una clase base con métodos que lanzan errores para indicar que deben ser implementados por una subclase. Esta clase define el contrato: cualquier adaptador de persistencia deberá proveer una implementación de add(task) y findAll().
Dominio: servicio de tareas (caso de uso)
Ahora implementamos un servicio de dominio que use ese puerto de repositorio. Este servicio actúa como puerto de entrada al núcleo de la aplicación para el caso de uso de gestión de tareas:
// dominio/TareaServicio.js (Lógica de negocio / caso de uso)
class TaskService {
/**
* @param {TaskRepository} taskRepository - Se inyecta una implementación de TaskRepository
*/
constructor(taskRepository) {
this.taskRepository = taskRepository;
}
// Caso de uso: crear una nueva tarea
crearTarea(titulo) {
const nueva = new Task(Date.now(), titulo, false);
this.taskRepository.add(nueva);
return nueva;
}
// Caso de uso: listar todas las tareas
obtenerListado() {
return this.taskRepository.findAll();
}
// Caso de uso: marcar una tarea como completada
marcarTareaCompleta(id) {
const tareas = this.taskRepository.findAll();
const tarea = tareas.find(t => t.id === id);
if (tarea) {
tarea.marcarComoCompletada();
// En un repositorio real, aquí podríamos persistir el cambio, ej: this.taskRepository.update(tarea);
return true;
}
return false;
}
}
En TaskService estamos encapsulando las operaciones de negocio relacionadas con tareas. Este servicio depende de una abstracción TaskRepository (que recibe vía constructor — esto es inyección de dependencias manual). Los métodos crearTarea, obtenerListado y marcarTareaCompleta implementan casos de uso de nuestra aplicación de tareas:
crearTarea(titulo): crea una nueva instancia deTaskcon un id (aquí usamosDate.now()para simplificar) y el título dado, luego utiliza el repositorio para guardarla. Devuelve la tarea creada.obtenerListado(): retorna todas las tareas obtenidas del repositorio.marcarTareaCompleta(id): busca en el repositorio la tarea con el id dado y, si la encuentra, invoca el método de dominiomarcarComoCompletada()de la entidad. Aquí, dado que usamos un repositorio en memoria, modificamos el objeto en sí; en una implementación real probablemente habría un método del repositorio para actualizar la tarea persistida.
Notemos que TaskService no sabe nada de cómo se almacena la tarea; solo llama métodos de taskRepository. Podríamos tener hoy un repositorio en memoria y mañana reemplazarlo por uno que use una base de datos, sin cambiar este servicio. TaskService es parte del dominio (contiene lógica de negocio como generar ID, marcar estados, etc.) y actúa como puerto de entrada (podemos considerarlo la interfaz de aplicación que los adaptadores de entrada utilizarán, por ejemplo un controlador web llamaría a estos métodos).
Adaptador de salida: repositorio en memoria
Implementemos ahora un adaptador concreto para el puerto de salida TaskRepository. Haremos un repositorio simple que guarda las tareas en una lista en memoria:
// adaptadores/persistencia/RepoMemoriaTareas.js (Adaptador secundario - implementación en memoria)
class InMemoryTaskRepository extends TaskRepository {
constructor() {
super();
this.tasks = []; // Aquí almacenamos las tareas en un array
}
add(task) {
this.tasks.push(task);
return task;
}
findAll() {
// Devolvemos una copia superficial del array para evitar mutaciones externas
return [...this.tasks];
}
}
InMemoryTaskRepository extiende TaskRepository e implementa sus métodos. Internamente utiliza un arreglo this.tasks para guardar las tareas añadidas. El método add(task) inserta la nueva tarea en el array y la retorna (opcionalmente podríamos retornar solo el id, etc., pero para este ejemplo devolver la tarea completa está bien). El método findAll() devuelve una copia del array de tareas. Usamos una copia ([...this.tasks]) para que quien reciba la lista no pueda modificar directamente nuestro array interno (una pequeña medida de seguridad en memoria).
Este adaptador es muy sencillo, pero ilustra el punto: cumple con el contrato (add y findAll) esperado por el dominio. El TaskService no necesita saber que es un array; podría ser una base de datos real, y su código no cambiaría. Si quisiéramos luego una persistencia en base de datos, crearíamos otro adaptador, por ejemplo DBTaskRepository que implementa add y findAll usando SQL o llamadas a una API, manteniendo la misma interfaz.
Uso de los puertos y adaptadores (montaje de la aplicación)
Por último, veamos cómo ensamblar estos componentes en el punto de entrada de la aplicación. Esto sería equivalente al adaptador primario en este ejemplo (aunque aquí es simplemente un script que llama al servicio, actuando como simulador de una UI):
// app.js (Punto de entrada - configura adaptadores y usa el servicio de dominio)
import { TaskService } from './dominio/TareaServicio.js';
import { InMemoryTaskRepository } from './adaptadores/persistencia/RepoMemoriaTareas.js';
// Inicializamos el adaptador de salida (repositorio) y el servicio de dominio
const taskRepository = new InMemoryTaskRepository();
const taskService = new TaskService(taskRepository);
// Simulamos algunas operaciones como si este código fuera una interfaz de usuario:
taskService.crearTarea("Comprar leche");
taskService.crearTarea("Sacar al perro");
taskService.crearTarea("Estudiar arquitectura hexagonal");
// Listar tareas actuales
const tareas = taskService.obtenerListado();
console.log("Tareas:", tareas);
// Marcar una tarea como completada (por ejemplo, la primera tarea)
if (tareas.length > 0) {
taskService.marcarTareaCompleta(tareas[0].id);
}
// Verificar el estado actualizado
console.log("Tareas actualizadas:", taskService.obtenerListado());
(El código anterior asume un entorno Node.js moderno donde podemos usar import/export; si no, podríamos usar require común de Node.)
En este fragmento, importamos el TaskService (dominio) y el InMemoryTaskRepository (adaptador). Creamos una instancia del repositorio en memoria y se la pasamos al TaskService. Esto configura la aplicación: ahora el servicio de tareas usará ese repositorio para las operaciones. Luego simulamos la interacción:
- Creamos tres tareas con distintos títulos.
- Obtenemos la lista de tareas y la mostramos por consola (en un contexto real, esto sería presentar en pantalla, o enviar en una respuesta HTTP, etc., pero aquí la consola es nuestra “vista”).
- Marcamos como completada la primera tarea de la lista.
- Volvemos a listar para verificar que esa tarea aparece con
completed: true.
Si ejecutamos este programa, la salida por consola podría ser algo así:
Tareas: [
Task { id: 1637450012231, title: 'Comprar leche', completed: false },
Task { id: 1637450012232, title: 'Sacar al perro', completed: false },
Task { id: 1637450012233, title: 'Estudiar arquitectura hexagonal', completed: false }
]
Tareas actualizadas: [
Task { id: 1637450012231, title: 'Comprar leche', completed: true },
Task { id: 1637450012232, title: 'Sacar al perro', completed: false },
Task { id: 1637450012233, title: 'Estudiar arquitectura hexagonal', completed: false }
]
Podemos notar que el servicio de dominio funcionó correctamente con el repositorio provisto. Si quisiéramos, podríamos ahora cambiar taskRepository por otra implementación (por ejemplo, DBTaskRepository) sin cambiar nada del TaskService ni del resto de la lógica de la aplicación. Así, hemos logrado nuestro objetivo de independencia.
¿Dónde están los puertos aquí? El puerto de salida es TaskRepository (interface) que el dominio usa, implementado por InMemoryTaskRepository. El puerto de entrada en este ejemplo implícitamente es el propio TaskService (podríamos formalizarlo más definiendo una interface para el servicio, pero no es estrictamente necesario en este caso). Nuestro app.js actuó como adaptador de entrada muy simple, llamando métodos del servicio como lo haría un controlador web o un script CLI.
Notas sobre la implementación
En un contexto real, probablemente usaríamos TypeScript u otro mecanismo para definir interfaces de forma más segura. También, el ensamblaje de dependencias (instanciar repos y pasarlos a servicios) podría delegarse a un contenedor de inversión de control. Sin embargo, incluso con JavaScript plano, podemos aplicar los principios de hexagonal: depender de abstracciones, inyectar implementaciones y mantener el núcleo desacoplado.
Este ejemplo es simplificado, pero demuestra la esencia: el dominio (crear, listar, marcar tareas) no depende de cómo o dónde se guardan las tareas. Podemos ejecutar la lógica con una base de datos distinta, con entradas distintas, y la funcionalidad permanece igual.
Training Microservicios y Event-Driven
Nivela a tu equipo en arquitecturas modernas. 4 sesiones con contenido personalizado.
Buenas prácticas al implementar arquitectura hexagonal
Al aplicar este patrón en proyectos reales, considera las siguientes recomendaciones para sacarle el máximo provecho:
-
Mantén el dominio puro: Asegúrate de que el código en la capa de dominio no importe módulos de infraestructura. Evita tentaciones como ejecutar consultas SQL directas, llamadas HTTP o manipular elementos de UI dentro del dominio. Todo acceso externo debe pasar por un puerto (interfaz). El dominio debería compilar y funcionar sin tener presentes las clases de frameworks o bases de datos.
-
Define puertos significativos: Identifica claramente qué operaciones del dominio necesitan ser accesibles desde fuera (puertos de entrada) y qué servicios externos necesita el dominio (puertos de salida). Dales nombres expresivos (por ejemplo,
RepositorioClientes,ServicioNotificaciones). Un puerto debe representar algo que tiene sentido desde la perspectiva del negocio, no un detalle técnico. Por ejemplo, un puerto de salida podría ser una interfazServicioDePagoen lugar deApiStripe; así, el dominio habla en términos de pago, sin casarse con un proveedor específico. -
Escribe adaptadores lo más simples posible: Los adaptadores idealmente no contienen lógica de negocio, solo traducen información y llaman al puerto correspondiente. Por ejemplo, un adaptador de entrada (como un controlador web) debería tomar los datos de la petición HTTP, convertirlos a tipos o objetos que entienda el dominio y llamar al servicio de dominio. Luego tomar la respuesta del dominio y formatearla (JSON, HTML, etc.) para la salida. Del mismo modo, un adaptador de salida (como un repositorio de BD) convierte las llamadas genéricas (ej.
guardar) en operaciones concretas (ej. query SQL). Mantener estos adaptadores delgados reduce duplicación de lógica y hace más sencilla su sustitución. -
Inversión de dependencias y DI: Usa la inyección de dependencias para pasar los adaptadores al dominio, ya sea manualmente (como en nuestro ejemplo
new TaskService(miRepositorio)) o mediante un framework de inversión de control. Esto hace explícito qué implementaciones está usando el dominio y te permite cambiarlas en pruebas o en diferentes despliegues. Por ejemplo, en tests unitarios podrías inyectar un repositorio falso o mock. En tiempo de producción, inyectas uno real. Todas las clases deberían depender de interfaces o clases abstractas (puertos), nunca de implementaciones concretas. -
Organización de paquetes por contexto: Organiza tu código de manera que refleje esta separación. En lugar de agrupar por tipo técnico (ej: controllers, services, repositories), agrupa por contexto o módulo de negocio, y dentro de cada uno separa subdirectorios para dominio y adaptadores. Así, físicamente evitas mezclas. Muchos proyectos siguen la convención de tener un módulo
domainy otroinfrastructureoadapters. También es común ver nombres comoapplication(para casos de uso, puertos de entrada) yinfrastructure(para adaptadores externos). -
No todo tiene que ser hexagonal al 100% desde el día uno: Aplica el patrón con criterio. Puede que ciertas partes de tu sistema no requieran tanta abstracción. Por ejemplo, si usas un framework web que te obliga a ciertos modelos, podrías inicialmente implementarlos y luego traducirlos a entidades de dominio internas. Trata de mantener la filosofía (dominio independiente), pero no dudes en adaptar detalles pragmáticos. La arquitectura debe servir al equipo y al proyecto, no convertirse en una carga dogmática.
-
Documenta las convenciones: Es útil anotar en el README o en documentos de arquitectura cuáles son los puertos definidos, qué adaptadores existen y cómo se conectan. Esto ayuda a nuevos colaboradores a entender rápidamente la estructura. Asimismo, si usas nombres genéricos (p.ej.,
Service,Repository), acompáñalos de contexto (por ejemploUserServiceen lugar de soloService) para que se identifique su rol fácilmente. -
Aprovecha DDD si es pertinente: La arquitectura hexagonal combina muy bien con Domain-Driven Design. Si el proyecto es complejo en términos de dominio de negocio, vale la pena diseñar bien las entidades, agregados, etc., y usar hexagonal para darles aislamiento. Los Servicios de aplicación de DDD equivalen a puertos de entrada, los Repositorios de DDD son puertos de salida, etc. DDD proporciona patrones tácticos que encajan naturalmente en este estilo arquitectónico.
-
Prueba en diferentes niveles: Aunque el dominio se pueda probar unitariamente, también realiza pruebas de integración para verificar que los adaptadores funcionan correctamente con el dominio. Por ejemplo, un test que use realmente el adaptador de base de datos (en un entorno de prueba) para asegurarse de que la app completa funciona de punta a punta. La arquitectura hexagonal facilita estas pruebas porque puedes arrancar la aplicación con distintos adaptadores (por ejemplo, una base de datos SQLite en lugar de producción) sin cambiar el código.
En síntesis, las buenas prácticas giran en torno a preservar la independencia del núcleo, mantener el código modular y comprensible, y no complicar más de la cuenta cuando no se necesita. Con el tiempo, un proyecto bien implementado con hexagonal tiende a resistir mejor los cambios y a evitar la “erosión” arquitectónica.
Conclusión
La arquitectura hexagonal es un poderoso paradigma que ayuda a construir software robusto, mantenible y flexible. Al colocar el qué hace la aplicación (su dominio) en el centro y relegar el cómo lo hace externamente a los bordes, logramos un diseño donde las decisiones tecnológicas pueden cambiar sin romper la esencia del sistema. Hemos visto cómo hexagonal compara con arquitecturas tradicionales, cuáles son sus piezas fundamentales (dominio, puertos y adaptadores) y los pros y contras de adoptarla. En la parte práctica, ilustramos con JavaScript cómo podría estructurarse una simple aplicación siguiendo estos principios, demostrando que no es necesario un framework sofisticado para empezar a aplicarlos.
Este estilo arquitectónico es adecuado para aplicaciones de cierto tamaño o complejidad, donde anticipamos cambios de requerimientos, evoluciones tecnológicas, o simplemente queremos facilitar la prueba y mantenimiento a largo plazo. Para desarrolladores principiantes, puede parecer un poco abstracto al principio, pero sus conceptos se relacionan con principios sólidos de diseño (separación de responsabilidades, inversión de dependencias) que conviene aprender. Para desarrolladores intermedios y avanzados, hexagonal proporciona un marco mental para organizar código de manera limpia, especialmente en conjunción con prácticas como pruebas automatizadas y DDD.
En conclusión, la arquitectura hexagonal (puertos y adaptadores) es una excelente herramienta en el repertorio de un desarrollador para crear sistemas escalables y preparados para el cambio. Al aplicarla, estarás siguiendo el consejo de Cockburn de hacer sistemas donde los detalles externos orbitan alrededor de un núcleo inmutable de negocio. Como todo, requiere práctica y adaptación al caso concreto, pero los beneficios en muchos escenarios justifican el esfuerzo.
Siguiente paso
Arquitectura y tu perfil profesional
Empieza con el diagnóstico gratis (~5 min). Si capacitas equipos en arquitectura moderna, revisa el training en microservicios.
Cuenta y novedades
Recibe recursos y avisos puntuales por correo. Complementa el paso principal de arriba.
