Clasificación de Patrones de Arquitectura de Software

En el desarrollo de software moderno, los patrones de arquitectura cumplen un rol fundamental al proporcionar soluciones reutilizables y probadas para problemas comunes en el diseño de sistemas. Comprenderlos y saber aplicarlos correctamente puede marcar la diferencia entre un sistema escalable, mantenible y resiliente, y otro que se vuelve frágil y difícil de evolucionar.
A medida que las aplicaciones se vuelven más complejas y distribuidas, surgen diferentes necesidades: desde cómo organizar el código internamente, hasta cómo permitir que cientos de servicios se comuniquen entre sí de manera segura y eficiente. En este contexto, no existe un único patrón universal que funcione para todos los escenarios; por ello, es esencial clasificar y entender los distintos tipos de patrones arquitectónicos según el propósito que cumplen.
Este artículo presenta una clasificación práctica y funcional de los principales patrones de arquitectura de software, segmentados según su enfoque: estructura del proyecto, comunicación entre componentes, orquestación de servicios, persistencia de datos, resiliencia, observabilidad y modelado de dominio. Además, se incluyen sugerencias para mejorar la comprensión y aplicación de estos patrones en entornos reales, como su relación con tipos de sistemas, nivel de abstracción y tecnologías actuales.
El objetivo es ofrecer una guía clara y completa tanto para arquitectos de software como para desarrolladores que buscan tomar mejores decisiones de diseño técnico.
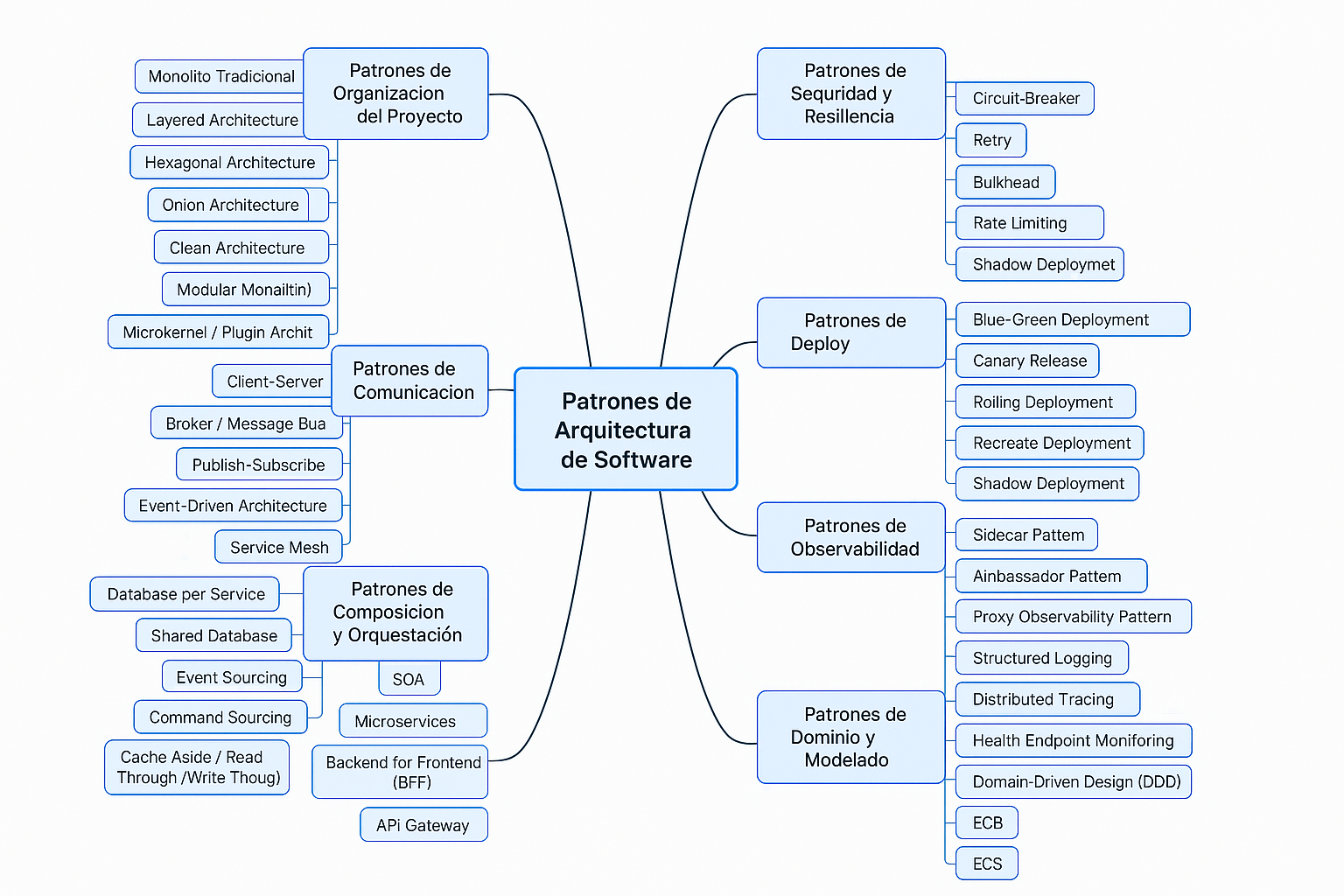
Patrones de Organización del Proyecto (Estructurales o Modulares)
Los patrones de organización del proyecto —también conocidos como estructurales o modulares— definen cómo se estructura internamente una aplicación o sistema, dividiendo sus responsabilidades en capas, componentes o módulos bien definidos. Estos patrones buscan mejorar la mantenibilidad, escalabilidad y capacidad de prueba del software, al promover principios como la separación de responsabilidades, el bajo acoplamiento y la alta cohesión.
A menudo son la base sobre la cual se construyen otras decisiones arquitectónicas, y resultan especialmente útiles al diseñar aplicaciones monolíticas limpias, así como también al preparar proyectos para migraciones hacia arquitecturas más complejas como microservicios.
A continuación, se describen los patrones más representativos en esta categoría:
Monolito Tradicional
El enfoque más simple y común en sistemas legados. Toda la aplicación —presentación, lógica y persistencia— se desarrolla y despliega como una sola unidad, sin separación de módulos internos. Aunque sencillo, este patrón tiende a volverse difícil de escalar y mantener a medida que el sistema crece.
Layered Architecture (Arquitectura en Capas)
Organiza el sistema en capas jerárquicas (por ejemplo: presentación, lógica de negocio, acceso a datos), donde cada capa solo puede comunicarse con la capa directamente inferior. Es uno de los patrones más clásicos y fáciles de implementar.
Hexagonal Architecture (Ports and Adapters)
Propone un núcleo de negocio aislado, rodeado de adaptadores que se conectan a entradas (como APIs o interfaces gráficas) y salidas (como bases de datos o servicios externos). Fomenta el desacoplamiento y la testabilidad.
Onion Architecture
Similar a la arquitectura hexagonal, organiza el sistema en anillos concéntricos, donde el dominio central es independiente de capas externas como infraestructura o frameworks. Promueve un diseño guiado por el dominio.
Clean Architecture
Popularizada por Robert C. Martin (Uncle Bob), combina ideas de Onion y Hexagonal Architecture. Plantea una división estricta entre capas (entidades, casos de uso, interfaces, frameworks), priorizando las reglas de negocio y facilitando la independencia de herramientas o tecnología.
Modular Monolith
Un enfoque que mantiene el sistema como un solo despliegue (monolito), pero internamente lo divide en módulos bien definidos, con límites claros y controlados. Ofrece muchos beneficios de los microservicios sin su complejidad operativa.
Microkernel / Plugin Architecture
Ideal para sistemas que requieren extensibilidad (como IDEs o plataformas), este patrón define un núcleo mínimo que ofrece capacidades básicas, y funcionalidades adicionales que se implementan como plugins. Facilita la evolución modular del sistema.
Patrones de Comunicación entre Componentes o Servicios
En sistemas distribuidos y arquitecturas modernas, la forma en que los distintos módulos o servicios intercambian información es crucial. Estos patrones definen mecanismos y estilos de comunicación que permiten a las distintas partes del sistema colaborar de forma eficiente, robusta y escalable.
Elegir el patrón adecuado depende del nivel de acoplamiento deseado, la necesidad de asincronía, la tolerancia a fallos, el rendimiento y otros factores clave como la trazabilidad o la interoperabilidad entre lenguajes o plataformas.
A continuación se describen los principales patrones de comunicación entre componentes o servicios:
Client-Server
Es uno de los modelos más clásicos. Un cliente realiza solicitudes a un servidor, que procesa la petición y devuelve una respuesta. Este patrón está en la base de muchas arquitecturas web y APIs modernas, incluyendo REST y GraphQL.
Broker / Message Bus
Introduce un intermediario (broker) para gestionar la comunicación entre productores y consumidores de mensajes. Este patrón desacopla los componentes, facilitando la escalabilidad y la extensibilidad del sistema. Ejemplos comunes: RabbitMQ, Apache Kafka, Azure Service Bus.
Publish-Subscribe
Permite que los componentes publiquen mensajes sin conocer quién los consume. Los suscriptores reciben automáticamente las notificaciones de eventos a los que están suscritos. Ideal para sistemas reactivos o notificaciones en tiempo real.
Event-Driven Architecture (EDA)
Un enfoque más amplio que el patrón publish-subscribe, donde los eventos son la unidad central de comunicación y flujo de control. Los servicios reaccionan a eventos que se producen en el sistema, permitiendo un diseño desacoplado, asincrónico y altamente escalable.
Service Mesh
Es una capa de infraestructura que facilita la comunicación entre microservicios, manejando automáticamente aspectos como descubrimiento de servicios, balanceo de carga, autenticación, encriptación, y observabilidad. Ejemplos populares: Istio, Linkerd.
REST, gRPC, GraphQL (Estilos de comunicación)
Aunque no son patrones arquitectónicos en sí mismos, estos estilos definen cómo se estructuran y transportan los datos entre componentes:
- REST: Usa HTTP y recursos con verbos estándar. Simple y ampliamente adoptado.
- gRPC: Basado en Protobuf y HTTP/2, permite comunicación binaria eficiente y contratos fuertes.
- GraphQL: Permite a los clientes definir exactamente qué datos requieren, optimizando las llamadas y reduciendo el over-fetching.
Patrones de Composición y Orquestación de Servicios
En arquitecturas distribuidas, como las basadas en microservicios, es común que múltiples servicios trabajen juntos para cumplir con una funcionalidad de negocio. Los patrones de composición y orquestación permiten estructurar esta colaboración, definir puntos de entrada, gestionar la lógica de interacción entre servicios, y coordinar flujos complejos, incluyendo transacciones distribuidas.
Estos patrones ayudan a organizar el comportamiento conjunto del sistema sin sacrificar la autonomía de cada componente, permitiendo tanto el acoplamiento flexible como el control estructurado de los procesos.
A continuación, se detallan los principales patrones de esta categoría:
Service-Oriented Architecture (SOA)
Modelo en el que la lógica de negocio se divide en servicios independientes, que se comunican a través de protocolos estándar (como SOAP o REST). Aunque menos ágil que los microservicios, SOA sentó las bases para arquitecturas distribuidas orientadas a servicios reutilizables.
Microservices
Arquitectura en la que cada servicio es pequeño, autónomo y responsable de una única funcionalidad del dominio. Cada microservicio puede desarrollarse, desplegarse y escalarse de manera independiente. Promueve equipos independientes y ciclos de entrega rápidos, aunque introduce complejidad operativa.
Backend for Frontend (BFF)
Patrón que propone crear una capa intermedia específica para cada tipo de cliente (web, móvil, etc.). Esta capa traduce y adapta los datos o flujos a las necesidades del frontend, evitando acoplamientos innecesarios con los microservicios core y mejorando la experiencia de usuario.
API Gateway
Un punto de entrada único para todas las llamadas a servicios backend. Se encarga de funciones transversales como autenticación, autorización, limitación de tasa, enrutamiento, agregación de respuestas y más. Mejora la seguridad y simplifica la interacción con servicios distribuidos.
Saga Pattern
Patrón para gestionar transacciones distribuidas en múltiples servicios, sin requerir bloqueo o transacciones distribuidas tradicionales. Se basa en una serie de pasos coordinados, cada uno con su operación de compensación en caso de fallo. Existen dos variantes principales: orquestadas (con un coordinador central) y coreografiadas (basadas en eventos).
CQRS (Command Query Responsibility Segregation)
Separa las operaciones de escritura (commands) y lectura (queries) en modelos distintos. Esto permite optimizar cada modelo para su propósito y escalar de forma independiente. Es comúnmente combinado con Event Sourcing y usado en sistemas complejos donde la consistencia eventual y la alta disponibilidad son prioritarias.
Patrones de Almacenamiento y Gestión de Datos
En arquitecturas distribuidas o sistemas con múltiples servicios, la forma en que se gestionan los datos es crítica para garantizar la consistencia, integridad, rendimiento y escalabilidad. Estos patrones definen cómo organizar las fuentes de datos, cómo sincronizar cambios, y cómo manejar la persistencia cuando múltiples componentes intervienen en el ciclo de vida de la información.
Seleccionar el patrón adecuado depende de factores como la necesidad de aislamiento de servicios, las exigencias de consistencia, la tolerancia a la latencia, y la frecuencia de lectura/escritura.
A continuación se presentan los principales patrones para manejar almacenamiento y gestión de datos:
Database per Service
Cada microservicio posee su propia base de datos, lo que refuerza la autonomía de los servicios y permite la elección de tecnologías especializadas (polyglot persistence). Esto mejora el aislamiento y evita cuellos de botella, pero complica la implementación de consultas o transacciones entre servicios.
Shared Database
Varios servicios acceden a una misma base de datos compartida. Facilita la implementación de relaciones y transacciones globales, pero rompe la independencia de los servicios y crea acoplamiento indeseado. Aunque es común en sistemas legados o monolitos, se recomienda evitarlo en arquitecturas modernas.
Event Sourcing
En lugar de almacenar el estado actual, se almacena una secuencia de eventos que representan cada cambio en el sistema. El estado actual se reconstruye reproduciendo estos eventos. Ofrece trazabilidad completa, historial auditable y facilita funcionalidades como rollback o reconstrucción del sistema.
Command Sourcing
Similar al Event Sourcing, pero se almacenan los comandos ejecutados en lugar de los eventos resultantes. Menos común, y requiere cuidado para mantener integridad, ya que los comandos pueden incluir decisiones de lógica de negocio no reproducibles.
Cache Aside / Read-Through / Write-Through
Patrones para integrar mecanismos de cache con sistemas de almacenamiento persistente:
- Cache Aside: El sistema consulta la base de datos si no encuentra el dato en caché, y luego lo almacena manualmente en la caché.
- Read-Through: El acceso a la caché se realiza de forma transparente, y si falta un dato, la cache se encarga de recuperarlo desde la base de datos.
- Write-Through: Las escrituras se hacen primero en la caché, que luego propaga los cambios a la base de datos.
Estos patrones ayudan a mejorar el rendimiento, reducir latencia y aliviar la carga sobre la base de datos.
Training Microservicios y Event-Driven
Nivela a tu equipo en arquitecturas modernas. 4 sesiones con contenido personalizado.
Patrones de Seguridad y Resiliencia
En entornos distribuidos, altamente escalables o expuestos a Internet, garantizar la resiliencia del sistema y su seguridad frente a errores, sobrecargas y ataques es fundamental. Estos patrones permiten construir sistemas que se autorecuperan, aíslan fallas, limitan el impacto de errores, y protegen los datos y accesos de forma robusta.
Aplicarlos correctamente puede marcar la diferencia entre un sistema caído por efecto dominó y uno que se mantiene operativo bajo presión o falla parcial.
A continuación, se presentan los patrones más relevantes en esta categoría:
Circuit Breaker
Actúa como un interruptor de protección que corta temporalmente las llamadas a un componente externo cuando se detecta un alto número de fallos consecutivos. Permite que el sistema degrade su funcionamiento en vez de colapsar, y se reintenta una vez que el servicio externo se estabiliza. Es un patrón clave para evitar fallas en cascada.
Retry
Permite reintentar una operación fallida (como una llamada a API o a base de datos) un número limitado de veces antes de considerarla definitivamente fallida. Se puede combinar con backoff exponencial para evitar congestión. Útil para manejar errores transitorios o intermitentes.
Bulkhead
Divide el sistema en compartimentos o contenedores independientes (como en los barcos) para aislar fallas. Si una parte del sistema falla o se satura, el resto puede seguir funcionando. Se usa para limitar recursos compartidos (hilos, conexiones, etc.) y prevenir el colapso total.
Rate Limiting
Restringe la cantidad de peticiones que un cliente o servicio puede realizar en un periodo de tiempo determinado. Es esencial para prevenir abusos, ataques de denegación de servicio (DoS), y sobrecarga de servicios internos. Puede aplicarse a nivel de API Gateway, servicio individual o incluso a funciones internas.
Authentication Gateway / Token-Based Authentication
Patrón de seguridad que centraliza la autenticación en un punto de entrada único (como un API Gateway), donde se validan tokens (JWT, OAuth, etc.) emitidos por un proveedor confiable. Protege los servicios internos y permite aplicar políticas de seguridad de forma unificada, escalable y desacoplada de la lógica de negocio.
Patrones de Deploy
Los patrones de deploy definen estrategias para realizar la puesta en producción de nuevas versiones de un sistema de forma segura, gradual y controlada. Estos patrones permiten minimizar riesgos, evitar tiempos de inactividad, y facilitar la reversión en caso de fallos. Son especialmente útiles en contextos de entrega continua, DevOps y arquitecturas modernas como microservicios o contenedores.
A continuación, se describen los patrones más comunes para gestionar despliegues:
Blue-Green Deployment
Este patrón mantiene dos entornos casi idénticos: uno activo que recibe tráfico (por ejemplo, azul) y uno pasivo (verde). La nueva versión se despliega en el entorno pasivo, se realiza la validación, y luego el tráfico se redirige completamente a ese entorno. Si algo falla, se puede revertir simplemente redirigiendo el tráfico al entorno anterior.
Canary Release
Consiste en desplegar una nueva versión de forma progresiva, comenzando con un pequeño porcentaje de usuarios o peticiones. Si el sistema se comporta correctamente, se incrementa la exposición hasta alcanzar el 100%. Este enfoque permite detectar errores o degradaciones sin afectar a todos los usuarios.
Rolling Deployment
En este patrón, las instancias de una aplicación se actualizan una a una (o en pequeños grupos), mientras el resto continúa operando con la versión anterior. No requiere infraestructura duplicada como en blue-green, pero puede ser más complejo de controlar en caso de errores en medio del proceso.
Recreate Deployment
Se detiene completamente la versión antigua de la aplicación antes de iniciar la nueva. Es el patrón más simple, pero implica un periodo de inactividad. Puede usarse en sistemas sin alta disponibilidad o donde se puede tolerar cierto downtime.
Shadow Deployment (o Release en Paralelo)
La nueva versión se despliega en paralelo a la existente y recibe tráfico duplicado (solo para observación, sin impactar al usuario). Permite validar comportamiento en condiciones reales sin afectar la operación. Es útil para probar cambios complejos, como migraciones de lógica o algoritmos.
Patrones de Observabilidad
La observabilidad es la capacidad de un sistema para ofrecer información útil sobre su estado interno a partir de datos externos como logs, métricas y trazas. En sistemas distribuidos, cloud-native o con microservicios, se vuelve esencial para detectar fallos, analizar comportamientos anómalos y garantizar el rendimiento en producción.
Los siguientes patrones ayudan a estructurar e implementar una observabilidad eficaz y automatizada:
Sidecar Pattern
Consiste en desplegar un contenedor o proceso adicional junto al servicio principal, compartiendo el mismo entorno. Este contenedor cumple funciones auxiliares como recolectar logs, exponer métricas, inyectar configuraciones dinámicas o manejar trazas. Es muy utilizado en arquitecturas basadas en Kubernetes y service mesh.
Ambassador Pattern
Funciona como un proxy que actúa como representante del servicio hacia el exterior. Permite interceptar y gestionar llamadas salientes del servicio, aplicando controles como reintentos, autenticación o trazabilidad. Es útil cuando se quiere mantener la lógica del servicio limpia y delegar responsabilidades transversales.
Proxy Observability Pattern
Se aplica un proxy (reversible o transparente) entre servicios o entre una aplicación y su base de datos para monitorear peticiones, latencias, errores y volúmenes de tráfico. Este enfoque permite observabilidad sin modificar el código fuente del servicio.
Structured Logging Pattern
Establece un formato uniforme para los logs, generalmente en JSON o key-value pairs, que facilita su análisis automático por herramientas de observabilidad (como ELK Stack, Loki o Datadog). Permite trazabilidad entre servicios cuando se integra con trazas y correlación de eventos.
Distributed Tracing Pattern
Consiste en rastrear una solicitud a través de múltiples servicios, identificando su recorrido, tiempo en cada componente y puntos de fallo. Se utilizan identificadores únicos de trazas y spans. Herramientas como OpenTelemetry, Jaeger o Zipkin permiten implementarlo en sistemas distribuidos.
Health Endpoint Monitoring
Establece endpoints expuestos por cada servicio para reportar su estado (por ejemplo, /health, /ready, /live). Los orquestadores o balanceadores usan esta información para enrutar tráfico o tomar decisiones de recuperación automática.
Patrones de Dominio y Modelado
Los patrones de dominio y modelado se centran en cómo estructurar la lógica de negocio de un sistema de forma clara, coherente y alineada con los procesos reales de la organización. Estos patrones ayudan a separar las reglas del negocio de detalles técnicos, facilitando el mantenimiento, la evolución del software y la colaboración entre desarrolladores y expertos del dominio.
Son especialmente útiles en sistemas complejos, donde las decisiones del negocio cambian frecuentemente, y es clave reflejar de manera precisa esas reglas dentro del sistema.
A continuación, se describen los principales enfoques y patrones usados para modelar dominios ricos:
Domain-Driven Design (DDD)
Un enfoque estratégico y táctico propuesto por Eric Evans para diseñar sistemas centrados en el dominio del negocio. DDD promueve la creación de un modelo conceptual compartido (Ubiquitous Language), y define elementos como entidades, objetos de valor, agregados, repositorios y servicios de dominio. Además, divide el sistema en contextos delimitados (Bounded Contexts) para gestionar la complejidad y evitar ambigüedades en el modelo.
Entity-Control-Boundary (ECB)
Patrón originado en el método ICONIX. Separa la lógica en tres componentes: Entity (representa objetos del dominio con identidad), Control (contiene la lógica de aplicación que coordina interacciones) y Boundary (interfaz entre el sistema y actores externos). Es útil para diseñar casos de uso con claridad y control de responsabilidades.
Entity-Component-System (ECS)
Muy utilizado en el desarrollo de videojuegos y simulaciones, este patrón separa los objetos en tres partes: Entities (identificadores únicos), Components (datos puros sin lógica) y Systems (procesos que actúan sobre los componentes). Facilita la flexibilidad y reutilización, permitiendo construir comportamientos complejos a partir de componentes simples.
Aggregates & Value Objects
Dos conceptos fundamentales dentro del DDD táctico. Un Aggregate es una unidad de consistencia y agrupación de entidades bajo una raíz, que garantiza reglas de integridad interna. Un Value Object, en cambio, no tiene identidad propia y representa atributos o conceptos con igualdad basada en valores (como una fecha o dirección). Estos patrones ayudan a modelar de forma explícita las reglas del negocio y mantener la integridad de los datos.
Siguiente paso
Arquitectura y tu perfil profesional
Empieza con el diagnóstico gratis (~5 min). Si capacitas equipos en arquitectura moderna, revisa el training en microservicios.
Cuenta y novedades
Recibe recursos y avisos puntuales por correo. Complementa el paso principal de arriba.
