Cómo crear un pipeline básico de entrenamiento de modelos
El entrenamiento de modelos de Machine Learning no se trata solo de aplicar un algoritmo a un conjunto de datos. Involucra una serie de pasos estructurados que deben ejecutarse correctamente para garantizar que el modelo aprendido sea confiable, reproducible y útil en producción. A esta secuencia de pasos se le conoce como pipeline de entrenamiento.
A continuación, veremos cómo construir un pipeline básico utilizando Python y scikit-learn, una de las librerías más populares para aprendizaje automático.
¿Qué es un pipeline de entrenamiento?
Un pipeline de entrenamiento es una secuencia estructurada de pasos que automatiza y estandariza el flujo de trabajo desde la entrada de datos hasta la generación del modelo entrenado. Esto puede incluir:
- Carga y limpieza de datos
- Preprocesamiento
- División del dataset
- Entrenamiento del modelo
- Evaluación
- Persistencia del modelo
Entorno de trabajo recomendado
Antes de comenzar, asegúrate de tener instalado lo siguiente:
pip install numpy pandas scikit-learn matplotlib joblib
También puedes usar entornos como Jupyter Notebook o Google Colab para seguir los pasos.
Estructura del proyecto
Para construir un pipeline básico de entrenamiento de modelos, puedes optar por estructurar tu código en un solo archivo o separarlo en módulos múltiples dependiendo del tamaño y propósito del proyecto.
Estructura en un solo archivo (ideal para aprendizaje y prototipos)
Si estás comenzando o simplemente construyendo un prototipo, puedes tener todo el código en un único archivo Python. Por ejemplo:
entrenamiento_modelo.py
Estructura modular
ml_pipeline/
│
├── data_loader.py # Carga y análisis de datos
├── preprocessing.py # Escalado, codificación, normalización
├── model_training.py # Entrenamiento del modelo
├── evaluation.py # Métricas y validación cruzada
├── persistencia.py # Guardar y cargar modelo
├── main.py # Ejecuta el pipeline completo
Cada archivo contiene funciones específicas y main.py orquesta todo el flujo:
# main.py
from data_loader import cargar_datos
from preprocessing import escalar_datos
from model_training import entrenar_modelo
from evaluation import evaluar_modelo
from persistencia import guardar_modelo
X_train, X_test, y_train, y_test = cargar_datos()
X_train_scaled, X_test_scaled = escalar_datos(X_train, X_test)
modelo = entrenar_modelo(X_train_scaled, y_train)
evaluar_modelo(modelo, X_test_scaled, y_test)
guardar_modelo(modelo)
Paso 1: Carga de datos
Uno de los primeros pasos en cualquier proyecto de Machine Learning es obtener y cargar un conjunto de datos representativo del problema a resolver. En este ejemplo usaremos el famoso dataset de Iris, un conjunto de datos clásico que se utiliza habitualmente para enseñar clasificación supervisada.
¿Qué es el dataset de Iris?
El dataset de Iris fue introducido por el estadístico y biólogo Ronald Fisher en 1936. Contiene 150 observaciones de flores de tres especies diferentes del género Iris: Iris setosa, Iris versicolor e Iris virginica.
Cada observación contiene 4 características (features) numéricas:
- sepal length (cm) – Largo del sépalo
- sepal width (cm) – Ancho del sépalo
- petal length (cm) – Largo del pétalo
- petal width (cm) – Ancho del pétalo
La tarea es predecir la especie de flor (la variable objetivo o target) a partir de estas características.
Este dataset es ideal para comenzar porque es pequeño, balanceado, bien estructurado y fácil de visualizar.
from sklearn.datasets import load_iris
import pandas as pd
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df["target"] = iris.target
print(df.head())
Paso 2: Análisis exploratorio y limpieza
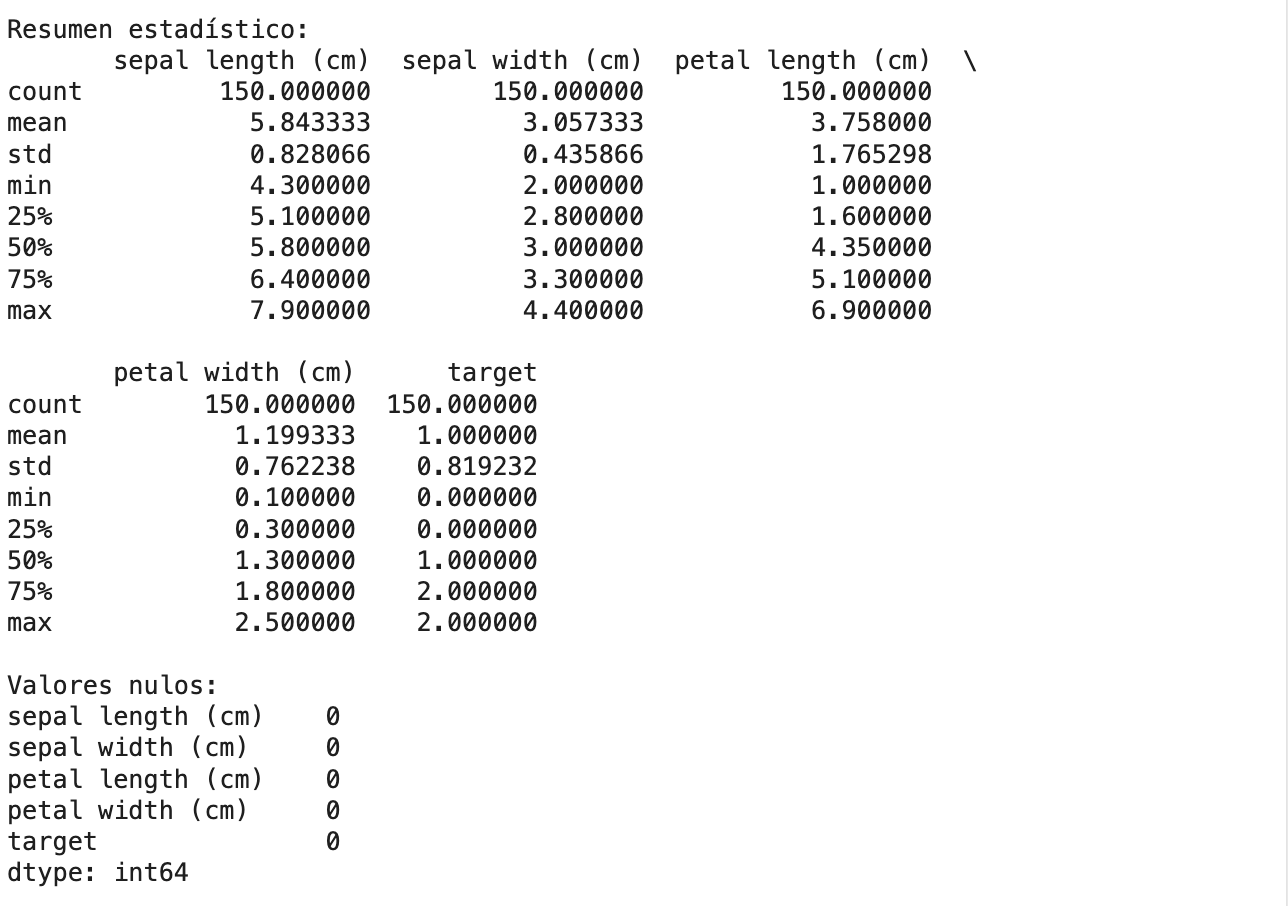
Antes de entrenar cualquier modelo, es fundamental realizar un análisis exploratorio de datos (EDA, por sus siglas en inglés). Este paso nos permite entender la estructura, distribución y calidad del dataset con el que estamos trabajando. En esta fase, analizamos estadísticas descriptivas como la media, desviación estándar, valores mínimos y máximos, y visualizamos la distribución de las clases objetivo para detectar posibles desbalances.
Además, se realiza una limpieza básica de datos, que incluye la detección de valores nulos o faltantes, la búsqueda de valores atípicos (outliers) y la verificación de tipos de datos incorrectos. Aunque en el dataset de Iris no hay valores nulos ni anomalías evidentes, en proyectos reales estos problemas son comunes y pueden afectar negativamente el rendimiento del modelo si no se abordan. Este paso asegura que los datos estén en condiciones óptimas para alimentar el modelo de aprendizaje automático.
print(df.describe())
print(df.isnull().sum()) # Verificamos si hay valores nulos
print(df["target"].value_counts()) # Verificamos el balance de clases
Para este dataset no hay valores faltantes, pero en proyectos reales probablemente debas tratar nulos y valores atípicos.
Paso 3: División del dataset
Una vez que tenemos un dataset limpio y comprendido, el siguiente paso esencial es dividir los datos en conjuntos de entrenamiento y prueba. Esto nos permite evaluar objetivamente el rendimiento del modelo, asegurando que no simplemente memorice los datos, sino que sea capaz de generalizar a información nueva.
En general, se utiliza entre un 70% y 80% de los datos para entrenamiento y el restante para prueba. El conjunto de entrenamiento se usa para ajustar los parámetros del modelo, mientras que el conjunto de prueba se mantiene apartado para validar cómo se comporta el modelo con datos que nunca ha visto. Esta práctica es clave para evitar el overfitting (cuando el modelo aprende demasiado los datos de entrenamiento y falla en datos reales). En Python, esta división se puede realizar fácilmente usando la función train_test_split de scikit-learn, que también permite establecer una semilla (random_state) para garantizar resultados reproducibles.
from sklearn.model_selection import train_test_split
X = df.drop("target", axis=1)
y = df["target"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Paso 4: Preprocesamiento y normalización
El preprocesamiento es una etapa crítica en cualquier pipeline de Machine Learning, ya que los algoritmos no trabajan bien con datos en bruto o desbalanceados en escala. En este paso nos enfocamos en normalizar o escalar las variables numéricas para que tengan una magnitud comparable. Esto es especialmente importante en modelos sensibles a la escala, como regresión logística, redes neuronales o SVM, donde diferencias grandes entre rangos pueden afectar negativamente el proceso de aprendizaje.
En este ejemplo, utilizamos el StandardScaler de scikit-learn, que transforma los datos para que tengan media cero y desviación estándar uno. Este proceso no modifica la distribución de las clases, pero sí asegura que todas las variables contribuyan de forma equitativa al cálculo de distancias y pesos internos del modelo. Es importante destacar que el escalador se ajusta (fit) solo con los datos de entrenamiento, y luego se transforman tanto el entrenamiento como el conjunto de prueba usando esa misma escala, para evitar fugas de información (data leakage).
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
Paso 5: Entrenamiento del modelo
Una vez que los datos han sido preprocesados, estamos listos para entrenar el modelo, es decir, enseñarle a identificar patrones y relaciones entre las características de entrada y la variable objetivo. En esta fase, se alimenta el conjunto de entrenamiento al algoritmo seleccionado, el cual ajusta internamente sus parámetros para minimizar el error de predicción.
En este ejemplo utilizamos regresión logística, un modelo de clasificación supervisada que funciona bien en tareas lineales como la del dataset de Iris. Aunque es un algoritmo relativamente simple, es una excelente opción para empezar por su eficiencia, interpretabilidad y buenos resultados en problemas bien definidos. Durante el entrenamiento, el modelo recibe ejemplos etiquetados y aprende a asignar probabilidades a cada clase posible. El resultado de esta etapa es un modelo ajustado que puede ser usado para hacer predicciones sobre nuevos datos.
Curso AI Software Engineering
Aprende a usar IA en el ciclo real de desarrollo: requerimientos, código, QA y documentación, con método y criterio técnico.
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(max_iter=200)
model.fit(X_train_scaled, y_train)
Paso 6: Evaluación del modelo
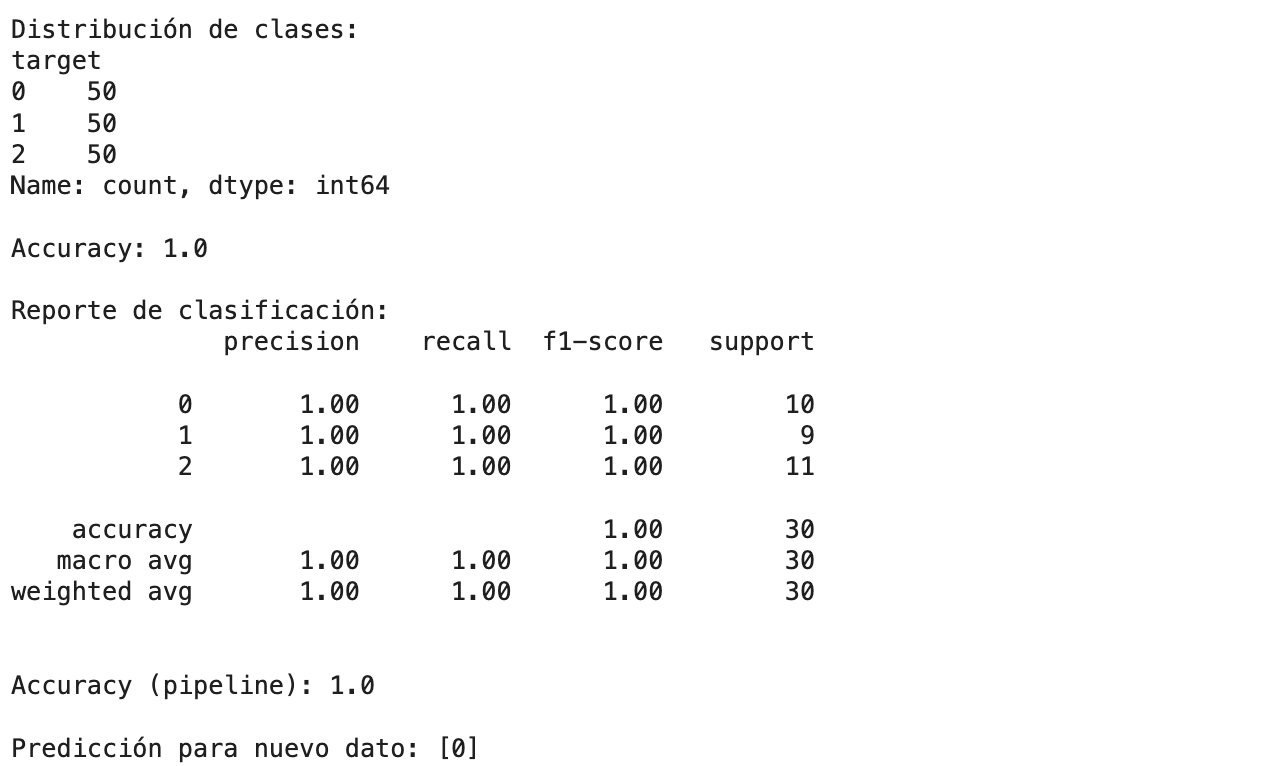
Después de entrenar el modelo, es fundamental evaluar su rendimiento para entender qué tan bien generaliza a datos nuevos. Esta evaluación se realiza utilizando el conjunto de prueba, que el modelo nunca ha visto durante el entrenamiento. Así obtenemos una medida objetiva de su capacidad predictiva.
En este paso se utilizan métricas como accuracy (precisión global), que indica qué proporción de predicciones fueron correctas, y el reporte de clasificación, que proporciona métricas más detalladas como precision, recall y f1-score por clase. Estas métricas son especialmente importantes cuando trabajamos con datasets desbalanceados o con múltiples clases, como es el caso del dataset de Iris. Evaluar el modelo permite detectar problemas como el sobreajuste (overfitting) o el subajuste (underfitting), y es clave para decidir si es necesario mejorar el preprocesamiento, ajustar hiperparámetros o probar con modelos más sofisticados.
from sklearn.metrics import accuracy_score, classification_report
y_pred = model.predict(X_test_scaled)
print("Accuracy:", accuracy_score(y_test, y_pred))
print("Reporte de clasificación:\n", classification_report(y_test, y_pred))
Paso 7: Guardar el modelo para producción
Una vez que el modelo ha sido entrenado y validado con buenos resultados, es momento de persistirlo, es decir, guardarlo en disco para que pueda ser reutilizado en otros entornos como desarrollo, testing o producción. Este paso es fundamental para integrar el modelo dentro de una aplicación web, backend o API sin tener que reentrenarlo cada vez que se ejecuta.
En Python, una forma común y eficiente de hacerlo es utilizando la biblioteca joblib, que permite serializar objetos complejos como modelos de scikit-learn o transformadores como StandardScaler. Es importante guardar tanto el modelo entrenado como el preprocesador, ya que cualquier dato nuevo que ingrese en producción debe pasar por el mismo flujo de transformación que se aplicó durante el entrenamiento. Esto asegura coherencia entre los datos que el modelo aprendió y los que evaluará en el futuro.
Una vez guardado, el modelo puede ser cargado fácilmente y usado para hacer predicciones sin repetir todo el pipeline de entrenamiento.
import joblib
joblib.dump(model, "modelo_entrenado.pkl")
joblib.dump(scaler, "escalador.pkl")
¿Qué es un escalador?
Un escalador (o scaler en inglés) es una herramienta utilizada en el preprocesamiento de datos que transforma los valores numéricos de las características para que estén en un rango común o tengan una distribución específica. En el contexto de Machine Learning, muchos algoritmos —como regresión logística, SVM, redes neuronales o KNN— se ven influenciados por la magnitud de los valores numéricos. Si una variable tiene un rango mucho mayor que las demás, puede dominar el proceso de aprendizaje y afectar negativamente al rendimiento del modelo. El escalado evita este problema al normalizar o estandarizar los datos.
Existen varios tipos de escaladores, y uno de los más comunes es el StandardScaler, que transforma los datos para que tengan media 0 y desviación estándar 1. Esto no elimina la forma de la distribución, pero centra los datos alrededor del cero, lo cual es ideal para muchos modelos estadísticos y redes neuronales. Otros escaladores populares son MinMaxScaler (que lleva los datos a un rango definido, típicamente de 0 a 1) y RobustScaler (menos sensible a valores atípicos). Elegir el escalador correcto depende del algoritmo que estés utilizando y de las características específicas de tu dataset.
Paso 8: Pipeline automatizado con Pipeline de scikit-learn
A medida que los proyectos de Machine Learning crecen en complejidad, es común que el código se vuelva difícil de mantener, especialmente cuando hay múltiples pasos como transformación de datos, escalado y entrenamiento. Para resolver esto, scikit-learn ofrece una poderosa utilidad llamada Pipeline, que permite encadenar múltiples pasos de procesamiento y modelado en un solo objeto reutilizable y limpio.
Un Pipeline garantiza que los pasos se ejecuten en orden correcto y previene errores comunes como fugas de datos (data leakage) entre el entrenamiento y la prueba. Por ejemplo, puedes definir un pipeline que primero escale los datos con StandardScaler y luego entrene un LogisticRegression. Esto hace que todo el flujo de entrenamiento sea más robusto, legible y fácilmente reutilizable para nuevas predicciones o validaciones cruzadas.
Además, el uso de Pipeline permite integrar estos flujos en tareas automatizadas como búsqueda de hiperparámetros (GridSearchCV), validación cruzada, o despliegue del modelo a producción, sin necesidad de gestionar manualmente cada transformación. Es una práctica estándar en cualquier entorno profesional de Machine Learning.
from sklearn.pipeline import Pipeline
pipeline = Pipeline([
("scaler", StandardScaler()),
("classifier", LogisticRegression(max_iter=200))
])
pipeline.fit(X_train, y_train)
# Evaluación
y_pred_pipeline = pipeline.predict(X_test)
print("Accuracy (pipeline):", accuracy_score(y_test, y_pred_pipeline))
Esto asegura que los pasos se ejecuten en orden y el código sea más mantenible.
Paso 9: Cómo reutilizar el modelo en producción
Una vez que el modelo y los pasos de preprocesamiento han sido guardados, el siguiente desafío es integrarlos en un entorno de producción para hacer predicciones sobre datos nuevos. Esto puede implicar su uso dentro de una API, un backend de una aplicación web o incluso un sistema embebido que toma decisiones en tiempo real.
Para reutilizar el modelo, simplemente se cargan los archivos serializados con joblib y se aplican las mismas transformaciones a los datos nuevos que las utilizadas durante el entrenamiento. Es crítico usar el mismo escalador (por ejemplo, StandardScaler) que fue ajustado con los datos originales, ya que entrenar uno nuevo sobre nuevos datos rompería la coherencia del pipeline y llevaría a predicciones erróneas.
Este proceso asegura que los datos entrantes sean transformados correctamente antes de ser ingresados al modelo, manteniendo la calidad y estabilidad del sistema en producción. Esta capacidad de reutilización es lo que permite que un modelo de Machine Learning se convierta en una herramienta útil y sostenible dentro de un producto o servicio tecnológico.
modelo = joblib.load("modelo_entrenado.pkl")
escalador = joblib.load("escalador.pkl")
nuevo_dato = [[5.1, 3.5, 1.4, 0.2]]
nuevo_dato_esc = escalador.transform(nuevo_dato)
prediccion = modelo.predict(nuevo_dato_esc)
print("Predicción:", prediccion)
Buenas prácticas adicionales
Validación cruzada
Puedes usar cross_val_score para validar mejor tu modelo:
from sklearn.model_selection import cross_val_score
scores = cross_val_score(model, X_train_scaled, y_train, cv=5)
print("Accuracy promedio:", scores.mean())
Revisión de sesgo y varianza
Compara el rendimiento en train y test para detectar overfitting.
Logging de métricas
Guarda métricas clave en archivos .json o base de datos para seguimiento.
Ejemplo completo
https://colab.research.google.com/drive/1K672kJlLoKCJWrF8vLDnOz0NjDQ2sd5a?usp=sharing
Resultados
Siguiente paso
IA aplicada al desarrollo (para ti)
Empieza con el diagnóstico gratis (~5 min) o conoce el curso AI Software Engineering para aplicar IA con método en tu trabajo técnico.
Cuenta y novedades
Recibe recursos y avisos puntuales por correo. Complementa el paso principal de arriba.
