Patrones de Arquitectura Batch
Los procesos batch (o procesos por lotes) han sido una parte fundamental del procesamiento de datos desde los primeros días de la computación. A pesar de la evolución hacia arquitecturas en tiempo real y eventos en streaming, los procesos batch siguen siendo esenciales en múltiples industrias. En este artículo, exploraremos por qué existen los procesos batch, su historia, patrones de arquitectura comunes y cómo han evolucionado en la era moderna.
¿Por qué existen los procesos batch?
Los procesos batch nacieron como una solución a varios problemas fundamentales en el procesamiento de datos, incluyendo:
- Limitaciones de hardware: En las primeras computadoras, los recursos eran escasos y costosos. Los procesos batch permitían agrupar tareas y ejecutarlas de manera eficiente en momentos de menor carga.
- Procesamiento de Grandes volumenes de datos: Permiten realizar grandes volúmenes de procesamiento sin la necesidad de interacción humana continua, optimizando recursos y reduciendo costos.
- Automatización de tareas repetitivas: Muchas tareas administrativas y operacionales, como la facturación, generación de reportes y cálculos financieros, pueden ejecutarse automáticamente en horarios programados.
- Procesamiento de datos en bloque: Muchos sistemas generan grandes volúmenes de datos que necesitan ser procesados de manera consolidada antes de ser utilizados.
Historia de los Procesos Batch
La historia de los procesos batch se remonta a los primeros sistemas operativos de computación, cuando el procesamiento en tiempo real no era viable debido a las limitaciones del hardware.
En la década de 1950, los primeros mainframes, como el IBM 701, utilizaban tarjetas perforadas para ingresar datos y ejecutaban tareas en lotes sin requerir la interacción del usuario.
Durante las décadas de 1960 y 1970, IBM desarrolló el Job Control Language (JCL) en el sistema operativo OS/360, lo que permitió la automatización de procesos batch, facilitando la ejecución programada de tareas repetitivas.
En los años 80 y 90, con la llegada de bases de datos relacionales y sistemas ERP, los procesos batch se volvieron fundamentales en el ámbito financiero, siendo utilizados en cálculos de nóminas, generación de reportes y análisis de datos.
A partir de los años 2000, con la explosión del Big Data, estos procesos se integraron con arquitecturas distribuidas usando Hadoop y Spark, así como con entornos de procesamiento en la nube.
En la actualidad, aunque muchas aplicaciones han migrado a arquitecturas en tiempo real, el procesamiento batch sigue siendo esencial en tareas como ETL (Extract, Transform, Load), machine learning offline y facturación masiva, demostrando su relevancia en la gestión eficiente de grandes volúmenes de datos.
Patrones de Arquitectura Batch
Existen diversos patrones de procesamiento batch, cada uno diseñado para abordar necesidades específicas en el manejo de datos:
Batch Secuencial Tradicional
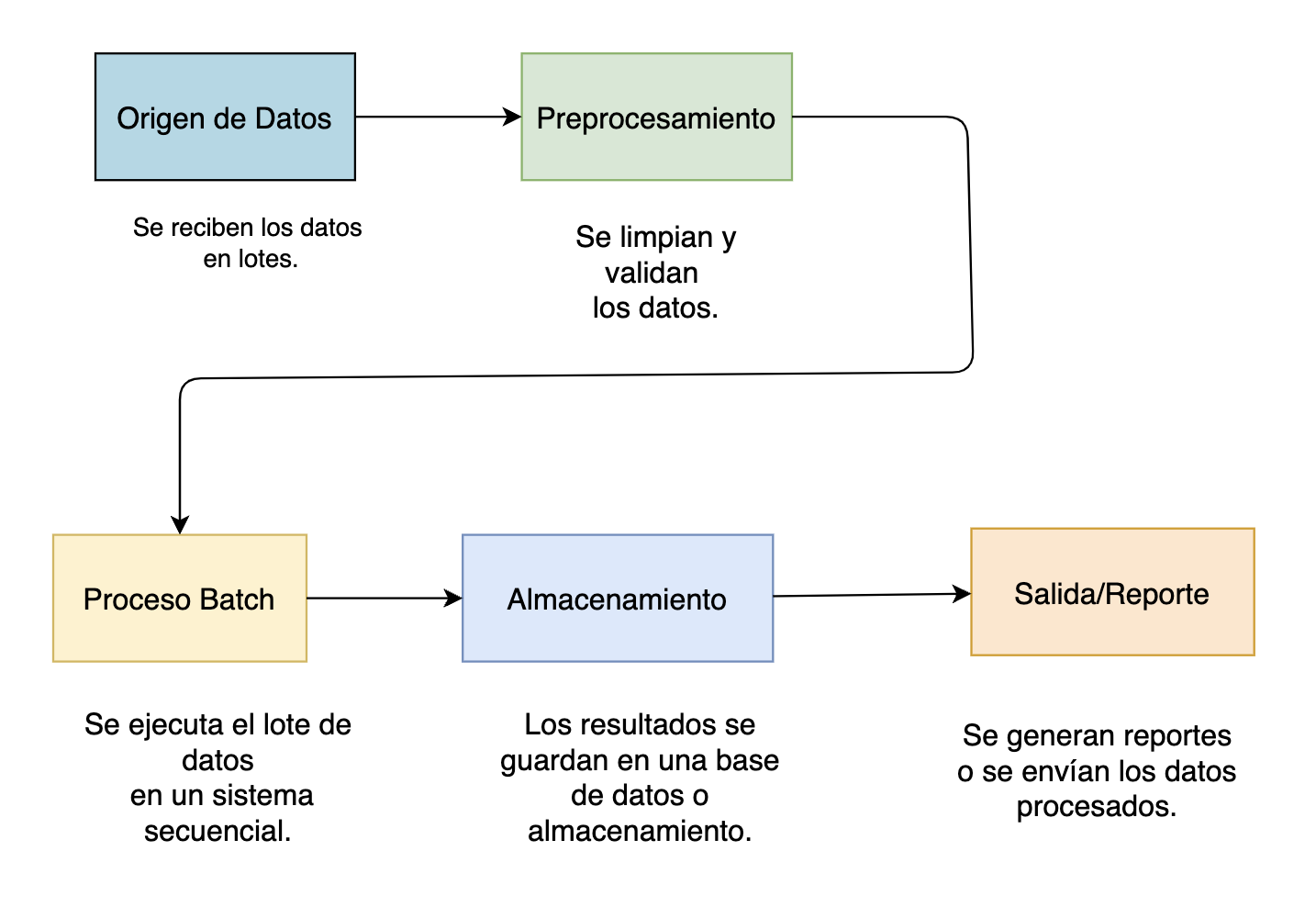
En el patron de Batch Secuencial Tradicional, las tareas se ejecuten en un orden predefinido dentro de un solo servidor o mainframe, sin concurrencia ni paralelización.
Este enfoque es particularmente útil cuando las operaciones deben seguir un flujo estrictamente definido para garantizar la integridad y consistencia de los datos procesados.
Un ejemplo clásico de este tipo de procesamiento es la generación de nóminas o facturación en sistemas financieros, donde cada etapa, desde la recopilación de datos hasta el cálculo de montos y la emisión de documentos, debe ejecutarse en secuencia para evitar errores y garantizar la precisión de los resultados.
Aunque este patrón puede ser menos eficiente en términos de tiempo de ejecución en comparación con arquitecturas distribuidas, sigue siendo ampliamente utilizado en entornos donde la estabilidad y la predictibilidad del proceso son más importantes que la velocidad de procesamiento.
Batch con Pipeline
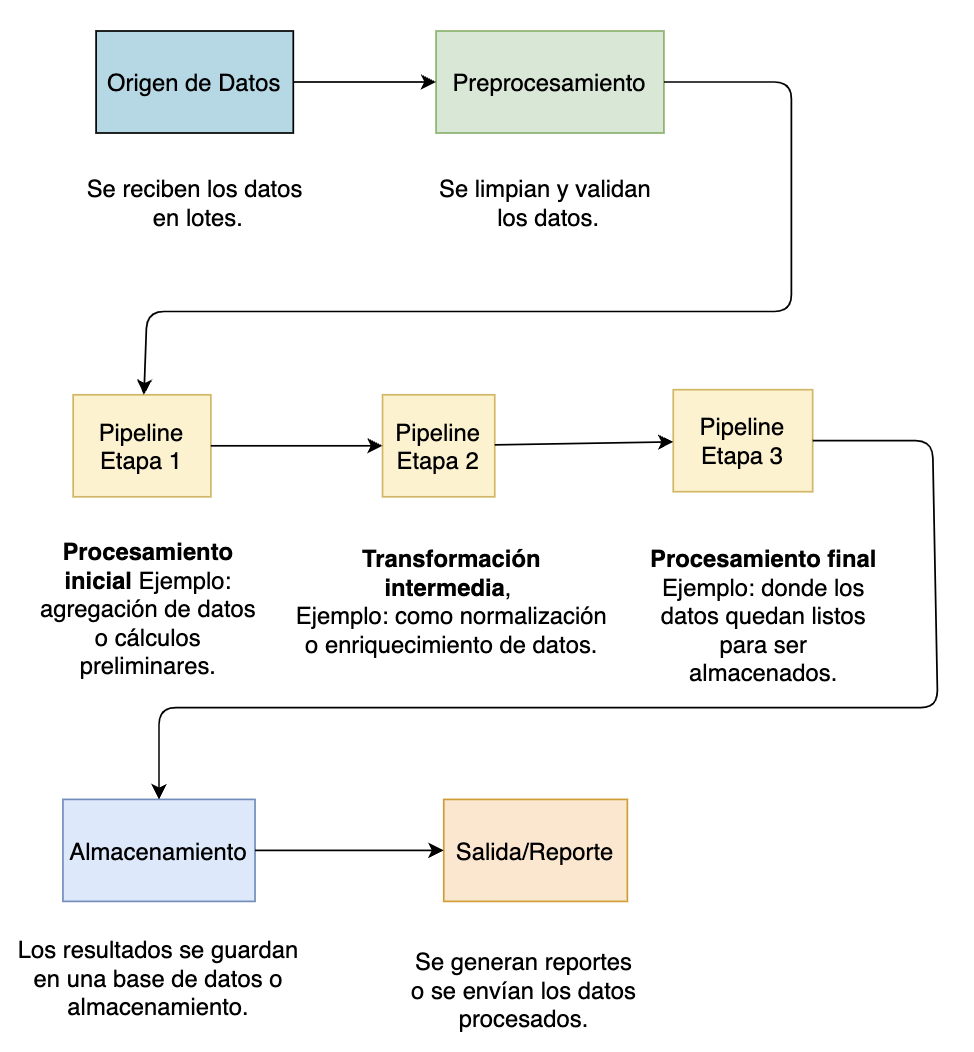
Otro patrón común en el procesamiento batch es el Batch con Pipeline, el cual divide un proceso grande en múltiples etapas interdependientes, donde cada una genera datos intermedios que alimentan la siguiente. Este enfoque permite una ejecución más estructurada y modular, facilitando la depuración, mantenimiento y escalabilidad del sistema.
A diferencia del batch secuencial tradicional, donde todo el procesamiento ocurre como una única tarea monolítica, en un pipeline batch cada etapa puede optimizarse de manera independiente e incluso ejecutarse en paralelo si las dependencias lo permiten.
Un ejemplo claro de este patrón es un pipeline de ETL (Extract, Transform, Load), en el que los datos se extraen de una fuente como una base de datos o almacenamiento en la nube, luego se transforman mediante procesos de limpieza, agregación o normalización, y finalmente se cargan en un sistema de destino como un data warehouse. Este enfoque no solo mejora la eficiencia del procesamiento de datos, sino que también permite una mayor flexibilidad al integrar nuevas etapas o modificar procesos sin afectar el flujo completo del pipeline.
Batch Distribuido (MapReduce)
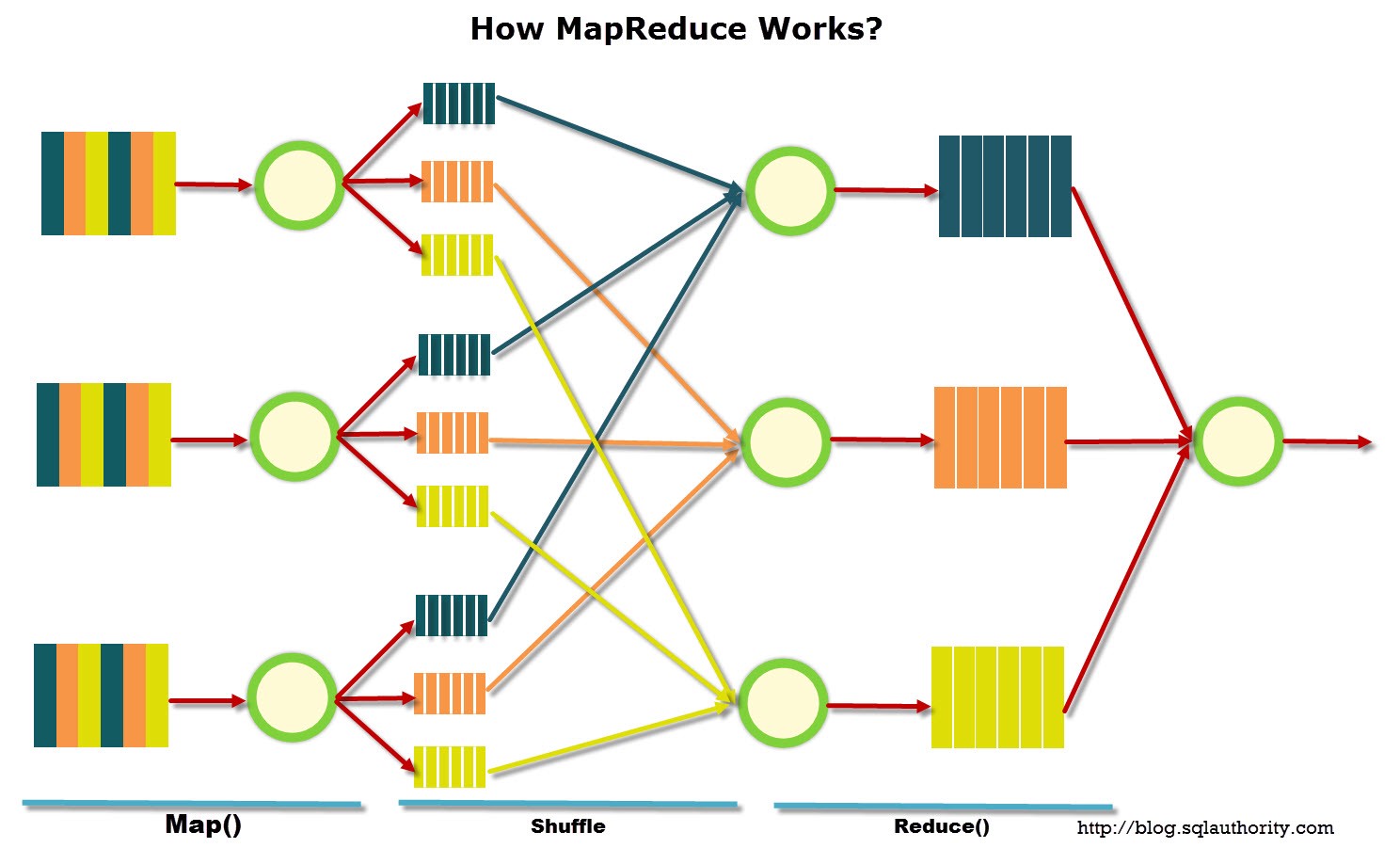
El Batch Distribuido, también conocido como MapReduce, es un patrón de procesamiento batch diseñado para manejar grandes volúmenes de datos dividiendo la carga de trabajo en múltiples nodos que procesan fragmentos de la tarea en paralelo. A diferencia de los enfoques tradicionales, donde un solo servidor ejecuta todo el proceso de manera secuencial, en este modelo la información se distribuye en un cluster de servidores, permitiendo un procesamiento altamente escalable y eficiente.
Este patrón es ideal para escenarios en los que se requiere manipular grandes cantidades de datos, como el análisis de logs, procesamiento de datos financieros o modelado de datos en machine learning.
Un ejemplo emblemático de este enfoque es el uso de Hadoop y Spark, donde un gran conjunto de datos se divide en pequeñas partes, cada una procesada en nodos separados dentro del cluster. Posteriormente, los resultados parciales se combinan para generar el resultado final. Este modelo no solo permite acelerar el tiempo de ejecución en comparación con procesos batch secuenciales, sino que también mejora la tolerancia a fallos, ya que si un nodo falla, su carga de trabajo puede ser reasignada a otro sin interrumpir el proceso completo.
Batch Event-Driven
El Batch Event-Driven es un patrón de procesamiento batch que no sigue un horario fijo de ejecución, sino que se activa en respuesta a eventos específicos dentro del sistema. A diferencia de los enfoques tradicionales donde los procesos batch se ejecutan en intervalos predefinidos, en este modelo la ejecución ocurre solo cuando hay datos nuevos o cambios relevantes que requieren procesamiento. Esto permite una mayor eficiencia, ya que evita el desperdicio de recursos ejecutando tareas innecesarias cuando no hay información nueva que procesar.
Un ejemplo típico de este patrón es un sistema de facturación automatizado, donde los reportes financieros no se generan a una hora determinada del día, sino únicamente cuando se detectan nuevas transacciones en la base de datos.
Este modelo es ampliamente utilizado en arquitecturas basadas en eventos, aprovechando tecnologías como colas de mensajería, servicios de notificación y plataformas serverless para optimizar el flujo de datos.
Gracias a su capacidad de respuesta inmediata, el Batch Event-Driven es ideal para escenarios en los que se requiere procesamiento flexible, reducción de latencia y mayor escalabilidad, integrándose perfectamente con sistemas modernos en la nube.
Batch Híbrido (Batch + Streaming)
El Batch Híbrido (Batch + Streaming) es un patrón arquitectónico que combina el procesamiento batch tradicional con arquitecturas de streaming para manejar cargas de trabajo mixtas.
Mientras que el batch se encarga de procesar grandes volúmenes de datos de manera consolidada en intervalos específicos, el streaming permite analizar información en tiempo real a medida que los datos llegan al sistema.
Este enfoque es especialmente útil en escenarios donde se requiere una respuesta inmediata para ciertos eventos, pero también se necesita un análisis más profundo y detallado en procesos periódicos. Un ejemplo de este patrón es un sistema de detección de fraudes, donde las transacciones se monitorean en tiempo real para identificar comportamientos sospechosos, pero además se ejecutan lotes nocturnos para realizar análisis más exhaustivos de tendencias y patrones históricos.
La combinación de estos dos modelos permite optimizar el uso de recursos, reducir la latencia en la toma de decisiones y mejorar la precisión del análisis, asegurando que los datos sean procesados tanto en el momento en que ocurren como en evaluaciones retrospectivas más completas.
Este enfoque se implementa comúnmente en arquitecturas modernas de datos utilizando herramientas como Apache Kafka, Apache Flink, Spark Streaming y servicios en la nube como AWS Kinesis o Google Dataflow.
Training Microservicios y Event-Driven
Nivela a tu equipo en arquitecturas modernas. 4 sesiones con contenido personalizado.
Ventajas y Desventajas de los Procesos Batch
Los procesos batch han sido una piedra angular en el procesamiento de datos por décadas, ofreciendo eficiencia y confiabilidad en la ejecución de tareas repetitivas y de alto volumen. Sin embargo, su uso también presenta desafíos, especialmente en comparación con arquitecturas en tiempo real. A continuación, profundizamos en sus ventajas y desventajas.
Ventajas de los Procesos Batch
Los procesos batch ofrecen múltiples beneficios que los hacen ideales para tareas que no requieren respuesta inmediata. Algunas de sus principales ventajas incluyen:
✅ Optimización de recursos: Una de las principales razones por las que los procesos batch siguen siendo relevantes es su capacidad para ejecutarse en momentos de menor carga computacional. Esto permite a las empresas aprovechar los recursos de manera más eficiente, ejecutando tareas intensivas en horarios nocturnos o en períodos de baja actividad, reduciendo así costos en infraestructura y consumo energético. Por ejemplo, en entornos cloud, esto se traduce en la posibilidad de escalar recursos temporalmente para el proceso y luego apagarlos, optimizando aún más el gasto operativo.
✅ Fiabilidad y consistencia: Los procesos batch son altamente predecibles y estructurados, lo que garantiza que se ejecuten de manera controlada sin interferencias externas. Esto es especialmente útil en aplicaciones críticas como la facturación, procesamiento de nóminas o generación de reportes financieros, donde la precisión y la ejecución ordenada son esenciales. Al eliminar la intervención manual, también se reducen los errores humanos y se asegura la consistencia en los resultados.
✅ Escalabilidad mediante procesamiento distribuido: En la actualidad, muchas implementaciones batch han evolucionado para ejecutarse en clusters de procesamiento distribuido, lo que permite manejar volúmenes masivos de datos de manera más eficiente. Tecnologías como Apache Hadoop y Apache Spark permiten dividir los trabajos batch en múltiples nodos, logrando así un procesamiento en paralelo que reduce significativamente los tiempos de ejecución en comparación con enfoques secuenciales tradicionales.
✅ Automatización y reducción de intervención manual: Los procesos batch pueden integrarse con herramientas de orquestación como Apache Airflow, AWS Step Functions o Azure Data Factory, lo que permite una ejecución totalmente automatizada sin necesidad de intervención humana. Esto no solo ahorra tiempo operativo, sino que también mejora la productividad y permite que los equipos técnicos se enfoquen en tareas de mayor valor agregado.
Desventajas de los Procesos Batch
A pesar de sus beneficios, los procesos batch presentan ciertas limitaciones que pueden hacer que no sean la mejor opción en algunos escenarios:
❌ Alta latencia y falta de inmediatez: Una de las mayores desventajas del procesamiento batch es su incapacidad para manejar eventos en tiempo real. Debido a que los datos solo se procesan en intervalos programados, los usuarios pueden experimentar retrasos en la disponibilidad de información. Esto puede ser problemático en aplicaciones donde se requiere respuesta inmediata, como sistemas de monitoreo de seguridad, detección de fraudes o análisis de tendencias en redes sociales.
❌ Complejidad en la gestión y mantenimiento: Si bien los procesos batch pueden ser eficientes, su implementación en entornos distribuidos puede ser desafiante y costosa. Configurar, monitorear y mantener pipelines batch en plataformas como Hadoop, Spark o AWS Glue requiere conocimientos avanzados en arquitectura de datos, manejo de errores y escalabilidad. Además, a medida que los volúmenes de datos crecen, la optimización de estos procesos se vuelve más compleja, exigiendo estrategias como particionamiento de datos y tuning de rendimiento.
❌ Uso intensivo de almacenamiento y costos asociados: Dado que los procesos batch suelen requerir la acumulación de grandes volúmenes de datos antes de ser procesados, el almacenamiento temporal puede convertirse en un cuello de botella. En entornos empresariales, esto puede significar altos costos en almacenamiento en la nube (S3, Google Cloud Storage, Azure Blob) o en hardware local. Además, en algunos casos, mantener grandes volúmenes de datos sin procesar puede afectar el rendimiento general de otros sistemas que dependen de ellos.
¿Siguen siendo relevantes los procesos batch en la actualidad?
A pesar del auge de tecnologías en tiempo real como Apache Kafka, Apache Flink y arquitecturas event-driven, los procesos batch continúan desempeñando un papel fundamental en muchos sectores debido a su capacidad de manejar grandes volúmenes de datos de manera eficiente y estructurada. Aunque la tendencia actual apunta hacia sistemas de baja latencia y análisis en tiempo real, muchas aplicaciones no requieren procesamiento inmediato y pueden beneficiarse de la eficiencia y confiabilidad del batch.
En diversas industrias, los procesos batch siguen siendo la opción preferida para tareas que requieren procesamiento intensivo de datos, alta confiabilidad y consistencia en la ejecución. Algunas de las áreas donde este enfoque sigue siendo crucial incluyen:
1. Finanzas y Banca
El sector financiero es uno de los principales usuarios de procesos batch, ya que muchas de sus operaciones implican cálculos complejos y procesamiento de grandes volúmenes de transacciones históricas. Algunos casos de uso incluyen:
- Cálculo de riesgos financieros y modelos de predicción, donde se procesan millones de transacciones históricas para evaluar la exposición al riesgo.
- Generación de reportes regulatorios y auditorías, que requieren consolidar datos de múltiples fuentes y cumplir con normativas estrictas.
- Conciliación bancaria, donde se comparan grandes volúmenes de transacciones entre diferentes sistemas para detectar inconsistencias.
- Procesamiento de nóminas y pagos a proveedores, que generalmente se ejecutan en lotes periódicos para garantizar precisión en los cálculos.
2. Retail y E-Commerce
En la industria del retail, los procesos batch siguen siendo esenciales para manejar grandes volúmenes de datos generados por transacciones, inventarios y logística. Algunos ejemplos incluyen:
- Generación de facturas y procesamiento de pedidos en masa, donde se consolidan compras realizadas durante el día para facturación nocturna.
- Sincronización de inventarios entre múltiples tiendas y almacenes, asegurando que los datos reflejen con precisión el stock disponible.
- Análisis de comportamiento del cliente, utilizando datos históricos para personalizar promociones y estrategias de ventas.
- Optimización de logística y cadena de suministro, procesando grandes volúmenes de datos para mejorar rutas de entrega y reducir costos operativos.
3. Big Data y Análisis de Datos
El Big Data ha transformado la forma en que las empresas toman decisiones, y los procesos batch siguen siendo una herramienta clave en el análisis masivo de datos. Plataformas como Apache Hadoop y Apache Spark permiten procesar grandes volúmenes de información de manera distribuida. Algunos usos incluyen:
- Procesamiento de logs y análisis de tráfico web, donde grandes volúmenes de registros se analizan en lotes para detectar patrones y anomalías.
- Agregación y transformación de datos en data lakes, permitiendo estructurar información en formatos optimizados para análisis posterior.
- Cálculo de métricas de negocio en plataformas de Business Intelligence (BI), como reportes de ventas, tendencias de mercado y proyecciones.
4. Machine Learning y Ciencia de Datos
El entrenamiento de modelos de Machine Learning (ML) es un proceso intensivo en cómputo que se realiza en lotes debido a la cantidad de datos que necesita procesar. Algunos ejemplos incluyen:
- Entrenamiento de modelos predictivos utilizando datos históricos almacenados en batch para optimizar precisión y eficiencia.
- Preprocesamiento de datos para modelos de IA, donde se aplican transformaciones, limpieza y normalización a grandes conjuntos de datos antes de su uso en modelos de deep learning.
- Generación de datasets para validación y testing, asegurando que los modelos se entrenen con datos bien estructurados y balanceados.
- Ejecución de algoritmos de procesamiento masivo en imágenes o texto, como reconocimiento de patrones en imágenes médicas o análisis de sentimientos en redes sociales.
5. Gobierno y Salud
En sectores como gobierno y salud, donde la integridad de los datos y la seguridad son críticas, los procesos batch permiten consolidar información de múltiples fuentes y generar reportes clave. Ejemplos incluyen:
- Consolidación de registros médicos electrónicos (EHR), donde los datos de pacientes se actualizan en lotes para mantener consistencia.
- Generación de reportes de salud pública, como análisis de tendencias epidemiológicas o monitoreo de pandemias.
- Procesamiento de datos censales y estadísticos, permitiendo análisis demográficos basados en grandes volúmenes de información.
6. Infraestructura Cloud y DevOps
En la administración de infraestructura cloud, los procesos batch se utilizan para tareas de automatización, mantenimiento y optimización de recursos. Algunos casos incluyen:
- Procesos de backup y recuperación de datos, donde se ejecutan respaldos en lotes fuera de horarios de producción para minimizar impacto.
- Optimización de costos en entornos cloud, apagando y escalando instancias automáticamente según el uso.
- Análisis de seguridad y auditorías, ejecutando escaneos programados en busca de vulnerabilidades en sistemas.
- Limpieza y archivado de datos en sistemas de almacenamiento, evitando costos innecesarios por información obsoleta.
Siguiente paso
Arquitectura y tu perfil profesional
Empieza con el diagnóstico gratis (~5 min). Si capacitas equipos en arquitectura moderna, revisa el training en microservicios.
Cuenta y novedades
Recibe recursos y avisos puntuales por correo. Complementa el paso principal de arriba.
